设计类似朋友圈的信息流系统,提供发布动态,获取最新动态的功能。
Step 1 - 明确需求
以下列需求作为设计目标:
- 移动端 or web应用 or both?=> both
- 重要特性有哪些?=>用户能够发布动态并且查看其他朋友的动态
- 动态是按更新时间排序还是按其他方式排序,比如话题关注度,或者按朋友的亲密度排序。=>假设只按更新时间排序
- 单用户最多支持多少朋友关系?=> 5000
- 访问流量多大?=>日活1000万
- 动态可以包含图片和视频吗,还是只文本?=>可以包含图片和视频
Step 2 - 概要设计
将设计分成两部分:发布动态和生成信息流推送。
- 发布动态:当用户发布动态时,将动态写入缓存和数据库,并且将该动态推送给朋友的动态列表。
- 生成信息流推送:简单起见,假设只需要将全部朋友的动态按发布时间排序即可。
API设计
用于发布动态和获取信息流,以及添加朋友,删除朋友,一般用HTTP协议进行通信。这里只以发布动态和获取信息流为例进行设计。
发布动态API
使用HTTP POST方法,客户端发送给服务器,比如 POST /v1/me/feed,需要content和auth_token两项参数。
- content:动态的内容
- auth_token:用于认证
获取动态API
使用HTTP GET方法,比如 GET /v1/me/feed,需要auth_token参数。
发布动态流程
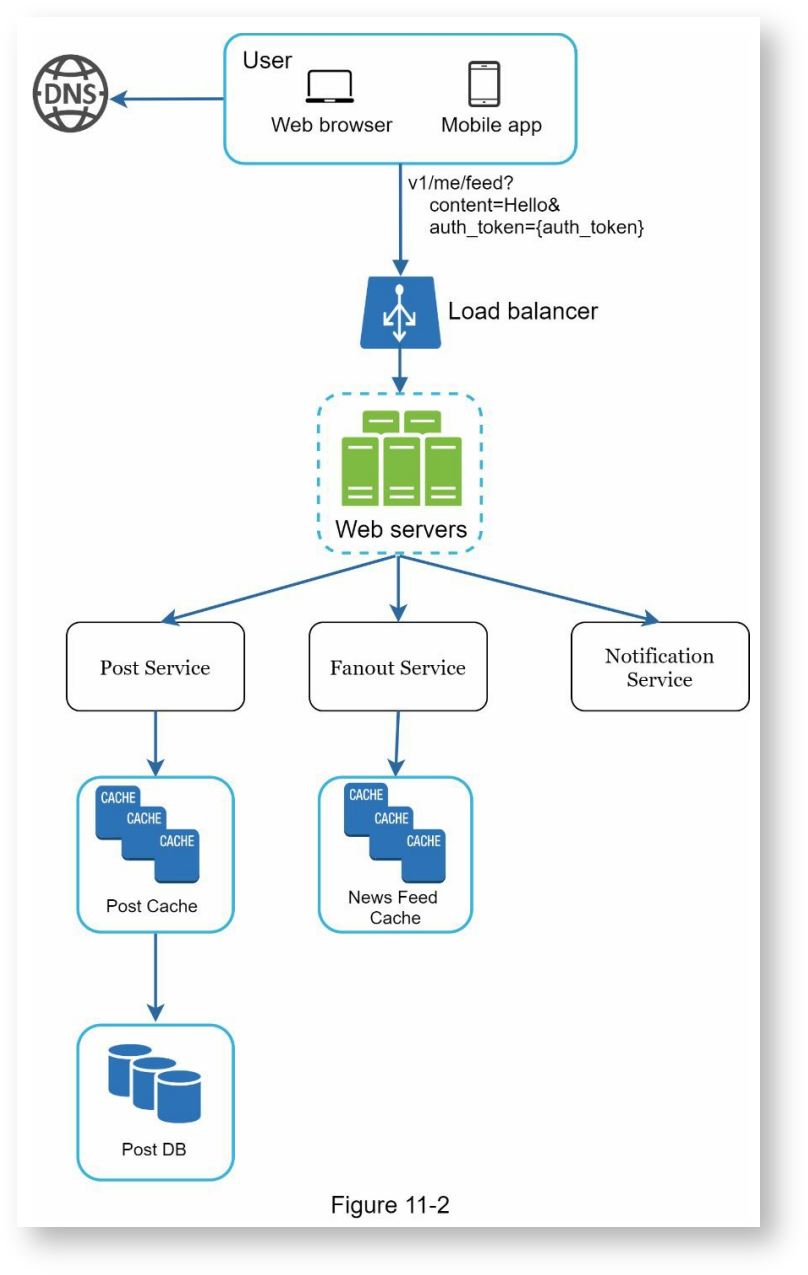
介绍几个组成部分。
- 用户:可以通过APP和网页浏览动态,也可以发布动态,比如
POST /v1/me/feed?content=Hello&auth_token={auth_token}。 - 负载均匀:将流量分布到各个服务器上
- Web服务器:将请求重定向到各个内部组件
- 动态服务:用于将发布的动态保存到数据库和缓存。
- 扇出服务:将动态推送给朋友的信息流,使用信息流缓存以加速读取。
- 消息推送:通知朋友有新动态可显示。
构造信息流
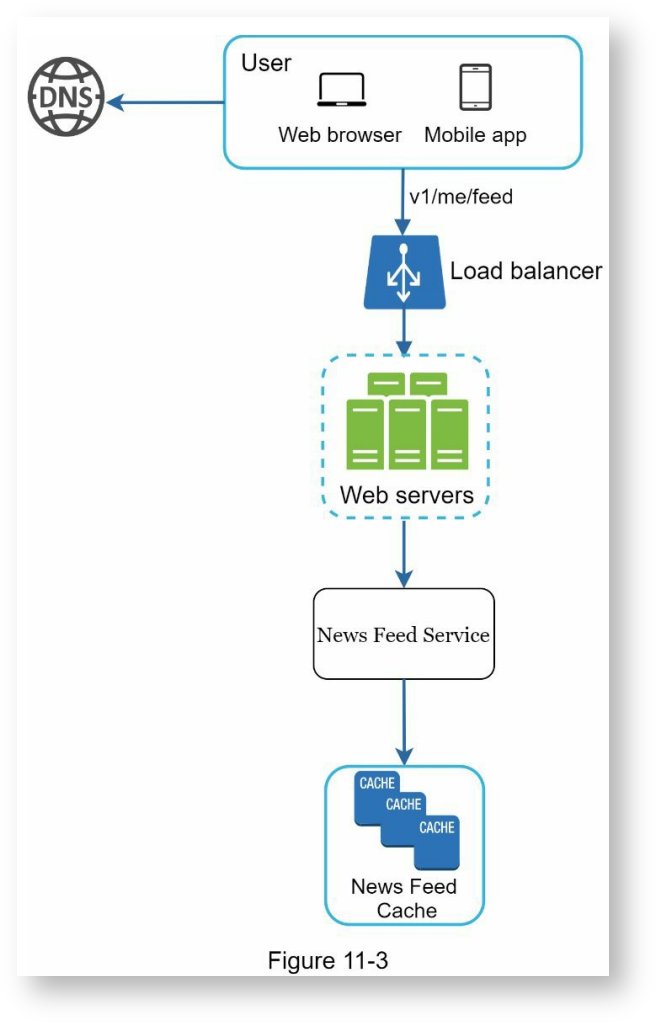
用户:发送请求以拉取最新的朋友圈动态,请求示例:GET /v1/me/feed。
负载均衡:将流量转发给web服务器
web服务器:将请求转发给信息流服务。
信息流服务:从信息流缓存中获取动态。
信息流缓存:存储用于构造信息流动的动态ID(post ID)。
Step 3 - 详细设计
包含两方面:发布动态和拉取信息流。
发布动态详细设计
重点关注两个组件:web服务和扇出服务。
web服务
除了和客户端通信,web服务器还需要执行认证和限流。只有携带合法的auth_token的用户才允许发布动态。系统对用户每段时间里能发布的动态数进行限制,以防止垃圾信息和内容滥用。
扇出服务
用于将动态传递给各个朋友。有两种典型的扇出模型:写时扇出和读时扇出。两种类型都有优缺点,以下是两种扇出类型的描述:
写时扇出:在发布动态时预先构造好信息流缓存。动态发布之后将其推送到朋友的信息流缓存里里,以支持快速读取。
优点:
- 实时构造信息流缓存,可快速推送给所有朋友。
- 可快速拉取信息流,因为信息流都已经预先构造好了并且存在缓存里。
缺点:
- 如果用户有很多朋友,那么获取朋友列表,并为每位朋友都生成信息流缓存是一项很耗时的工作,称为热点key问题。
- 对那些很少登录的用户,为他们预先构造好消息列表纯属浪费计算机资源(fuck)。
读时扇出:
在拉取动态时生成信息流,属于按需生成。
优点:
- 对于不活跃的用户,读时扇出可减少计算机资源浪费。
- 发布动态不会直接推送给所有朋友,不存在热点key问题。
缺点:
- 获取动态比较慢,因为没有提前扇出。
这里可以采用混合设计的方案以综合两种扇出模型的优缺点。对于大部分用户,我们使用写时扇出模型,对于名人或者朋友数量很大的用户,我们使用读时扇出,以减少服务器压力。一致性哈希可用于降低热点key问题的影响,因为它可以将数据平均地分布到各个服务器上。
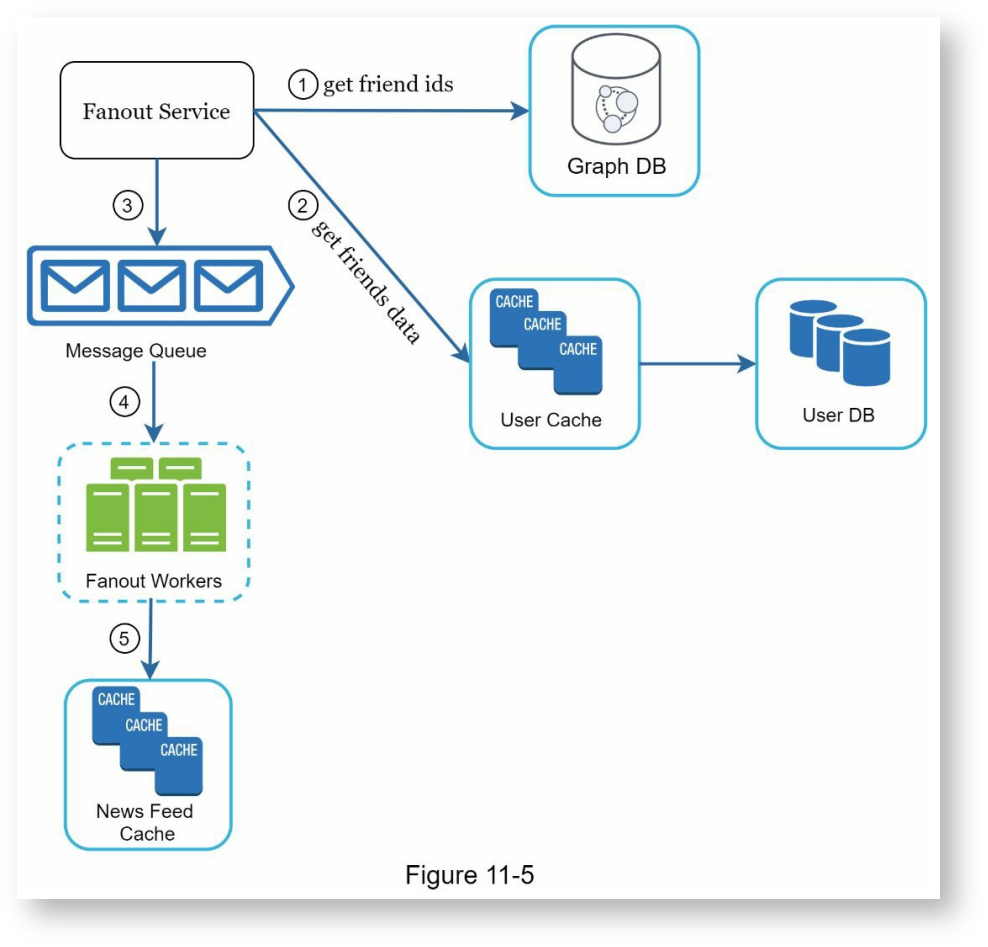
扇出服务工作流程如下:
- 从图数据库中获取朋友的ID列表。
- 从用户缓存中获取朋友的信息,也是一个列表。接下来系统根据用户的朋友圈设置来过滤掉不需要关注的朋友,比如你屏蔽了某人,则他的动态不会出现在你的动态列表里,或者用户希望只将动态展示给某些朋友或是对某些朋友进行屏蔽。
- 将朋友列表和新动态的ID发送给消息队列。
- 扇出集群从消息队列中取出数据,然后将新动态保存到每位朋友的信息流缓存中。每个用户都有单独的信息流缓存,对应朋友圈刷新时显示的动态列表。新动态被新增到每个朋友的信息流缓存里。这里可以将信息流缓存相像成<post_id, user_id>映射表。每当有朋友发布一条新动态时,新的动态都会被添加到缓存里。缓存所有用户的动态占用的内存非常巨大,所以,这里只存储ID。除此外,我们还可以限制存储数目,因为用户几乎不可能一次翻看几千条动态,大部分用户只对最新的动态感兴趣。
拉取信息流详细设计
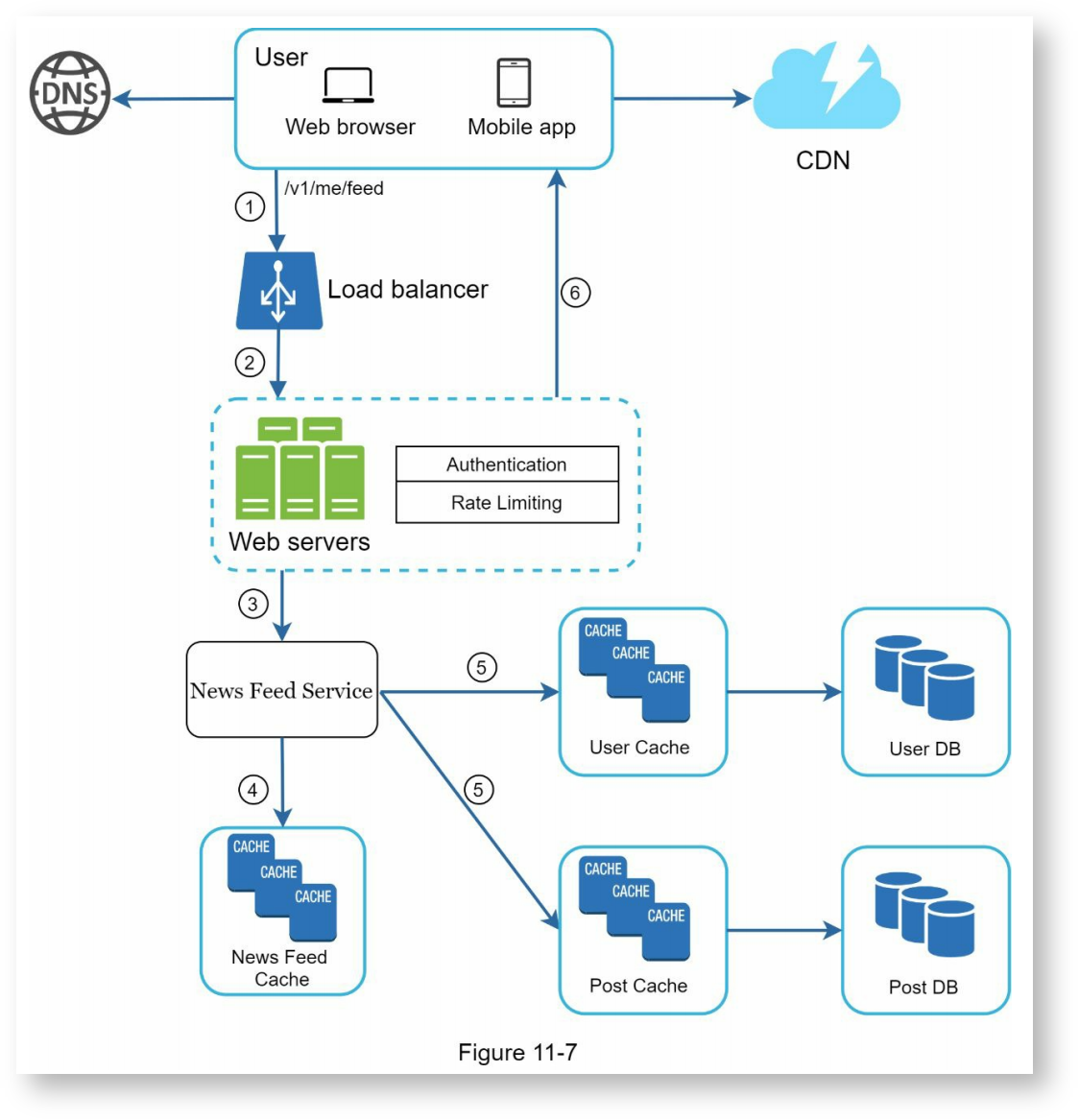
使用了CDN来缓存多媒体内容,比如图片,视频等,以下是拉取信息流的流程:
- 用户发送请求拉取动态,比如 GET /v1/me/feed。
- 负载均衡将请求转发给web服务器。
- web服务器调用信息流服务以获取动态列表。
- 信息流服务从信息流缓存中获取一系列的动态ID和用户ID。
- 信息流不仅仅包含动态ID,还包含用户名,头像,动态内容,动态图片等信息,因此,信息流服务还应该从各自的缓存中获取完事的用户信息、动态信息,以构造出完整的信息流。
- 以JSON的形式将构造完成的信息流返回给客户端进行渲染。
缓存构架
包含以下五层:
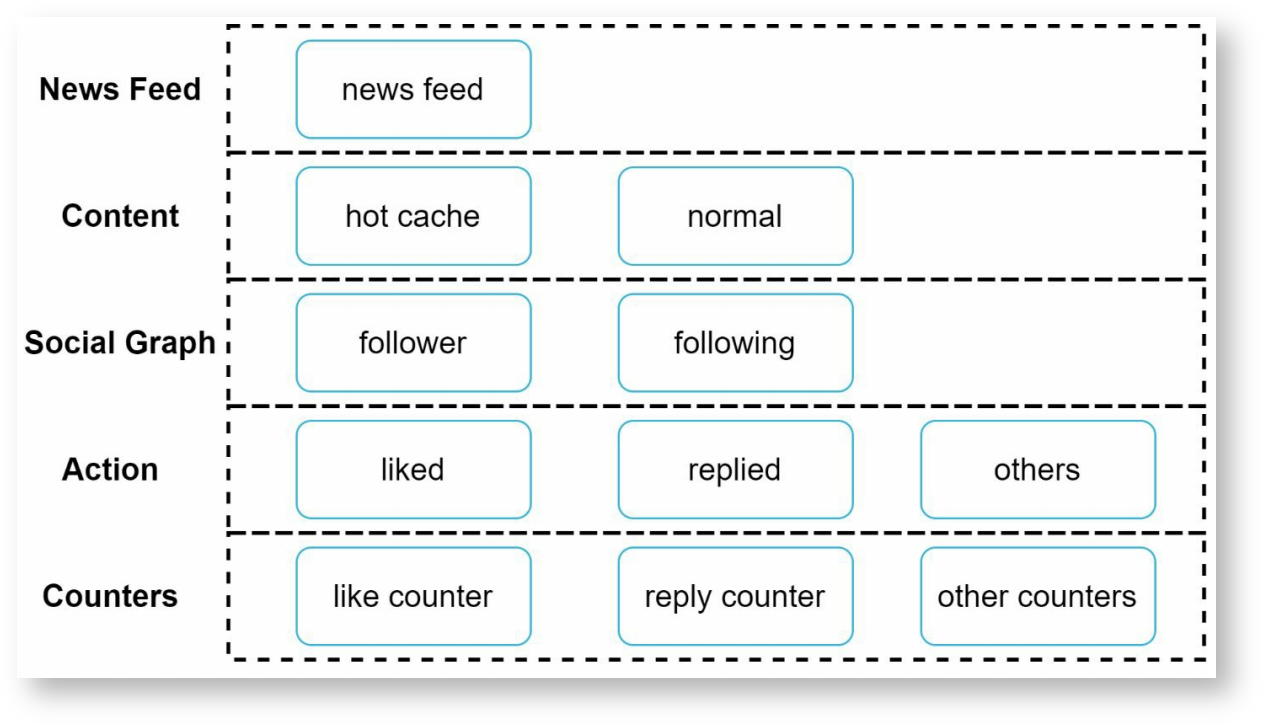
信息流:缓存信息流的ID。
内容:缓存信息流的内容。常用的内容存放在热点cache中。
社交关系图:存储用户关系,比如关注与被关注。
往为:存储用户是否喜欢过一条动态,或是评论过,或是其他行为。
计数器:存储点赞数,回复数,关注数,被关注数等。
Step 4 - 总结
可以几下点进行扩展:
数据库伸缩:
- 水平伸缩 vs 垂直伸缩
- SQL vs NoSQL
- 主从复制
- 读复制
- 一致性模型
- 数据库分片
其他点:
- 服务层无状态设计
- 尽可能多地缓存数据
- 支持多数据中心
- 使用消息队列触耦合
- 监控关键指标参数,比如QPS,峰值QPS,刷新延时等。