Step 1 - 明确需求
沟通并确定以下问题:
- 系统负载多大?=> 每天生成1亿条短地址
- 短网址长度有什么要求?=> 越短越好
- 短网址字符有什么要求?=> 字母加数字
- 已生成的短网址可更新或删除吗?=> 不允许
基本需求:
- URL压缩:给定长URL => 压缩成短URl
- URL重定向:给定短URL => 重定向到原始URL
- 高可用性,扩展性,以及容错能力
规模预估:
- 写操作:每天生成1亿条短地址
- 每秒写操作:1亿 / 24 / 3600 = 1160
- 读操作:假设读写比例是10:1,那么每秒的读操作是11600
- 假设服务持续运行10年,意味着必须记录 1亿*365*10 = 3650亿 条记录
- 存储需求:3650亿*100字节/条*10年= 365TB
Step 2 - 概要设计
讨论API接口,URL重定向,以及URL压缩流程。
API接口
设计REST风格的API接口,以提供短网址服务,一共有以下两个接口:
1. URL压缩,使用POST方法,客户端在请求中附带原始的URL参数,服务器返回经过压缩的短URL,这个方法的示例如下:
POST /api/v1/data/shorten
POST参数:{longURL: longURLString}
返回:短URL
2. URL重定向,使用GET方法,客户端提供短URL,服务器提供301或302重定向到原始URL,如下:
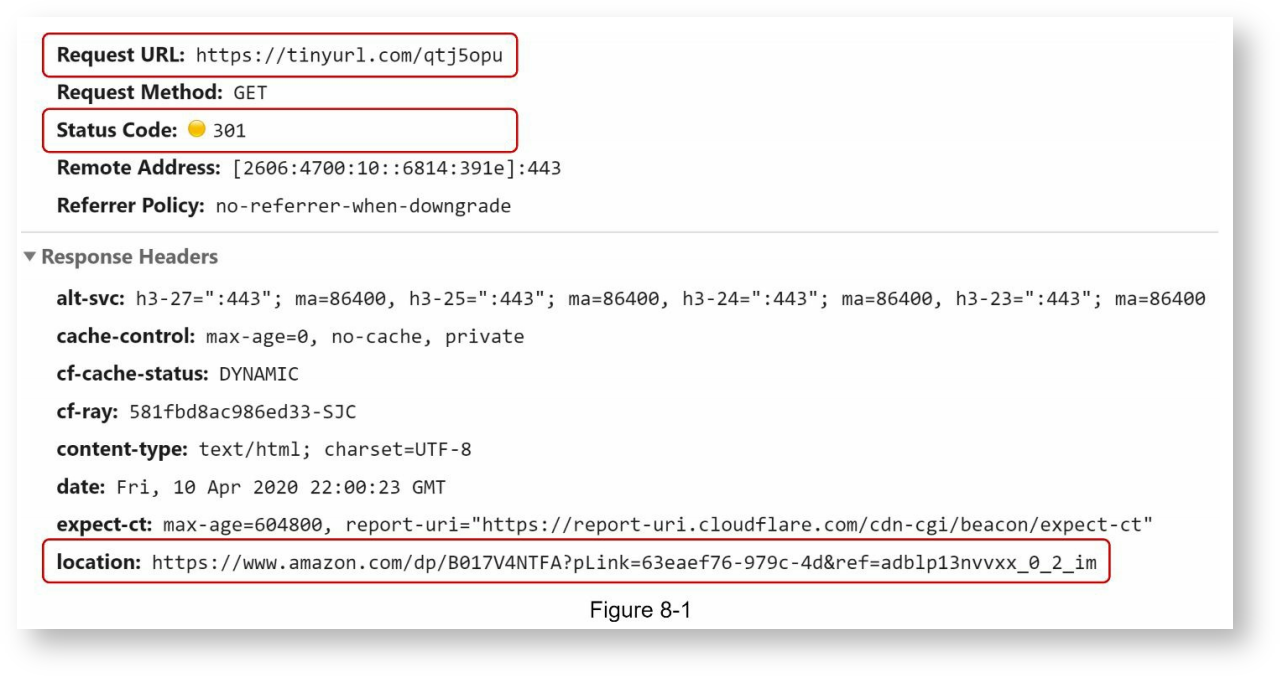
两种重定向:
301永久重定向:用于告知浏览器该地址被永久重定向到另一个地址,浏览器会缓存该信息,下次再访问相同的地址时,浏览器不再请求服务器,而是直接按缓存中的信息直接将链接重定向到新地址。只有在浏览器端清除缓存,才有可能改变对地址的重定向。
302临时重定向:用于告知浏览器该地址被临时重定向到另一个地址,浏览器不会缓存该信息,下次再访问相同的地址时,浏览器仍然会向服务器发起请求。
以上两种重定向方式,301永久重定向有助于降低服务器端的负载,因为只有第一次请示会发送到服务器,后续的重定向都由浏览器负责完成。但如果想在服务器端做流量统计,则必须使用302临时重定向。
URL压缩
整体来看,URL压缩可看成一个哈希操作,需要找到一个哈希函数fx,使得原始URL经过fx后变成短URL,如下:
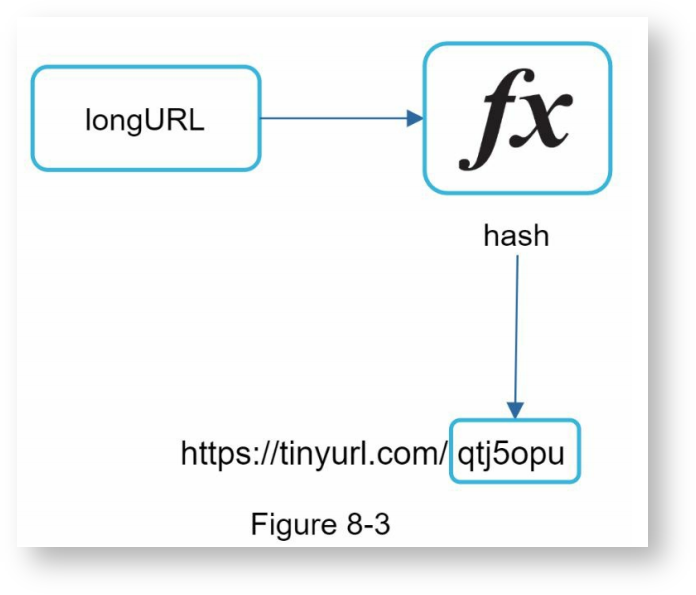
哈希函数fx必须满足以下特性:
- 长地址必须唯一地被映射到短地址
- 短地址可以被唯一地映射回长地址
Step 3 - 详细设计
讨论数据模型,哈希函数,URL压缩以及URL重定向。
数据模型
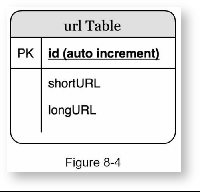
使用关系型数据库来存储短地址与原始地址的关系,数据库可以简单到只包含三列:id,shortURL, long URL,如下:
哈希函数
用于将长地址映射到一个短地址,也称为哈希值。
哈希值长度
按上面的讨论,短网址只能包含[0-9, a-z, A-Z]以内的字符,一共有10+26+26=62个可选字符。由于总共要3650亿条记录,在确定哈希值长度时,必须要保证长度n对应的62^n > 3650亿。经过一点点的计算可确定n=7时满足需求,所以哈希值长度为7,也就是短地址只需要使用7位字符来表示。
哈希+冲突检测算法
先使用一些知名的哈希算法对长网址计算哈希值,以下是分别使用CRC32, MD5, SHA-1对https://en.wikipedia.org/wiki/Systems_design进行计算的结果:

在这些算法结果的基础上,选出起始的7位作为最终结果。很明显这样会导致哈希冲突,为了处理冲突,我们在长网址的基础上再加一个预定义的字符串进行计算,生成一个新的哈希结果,再取前7位,直到不再冲突为止。以下是这种方法的示意图:
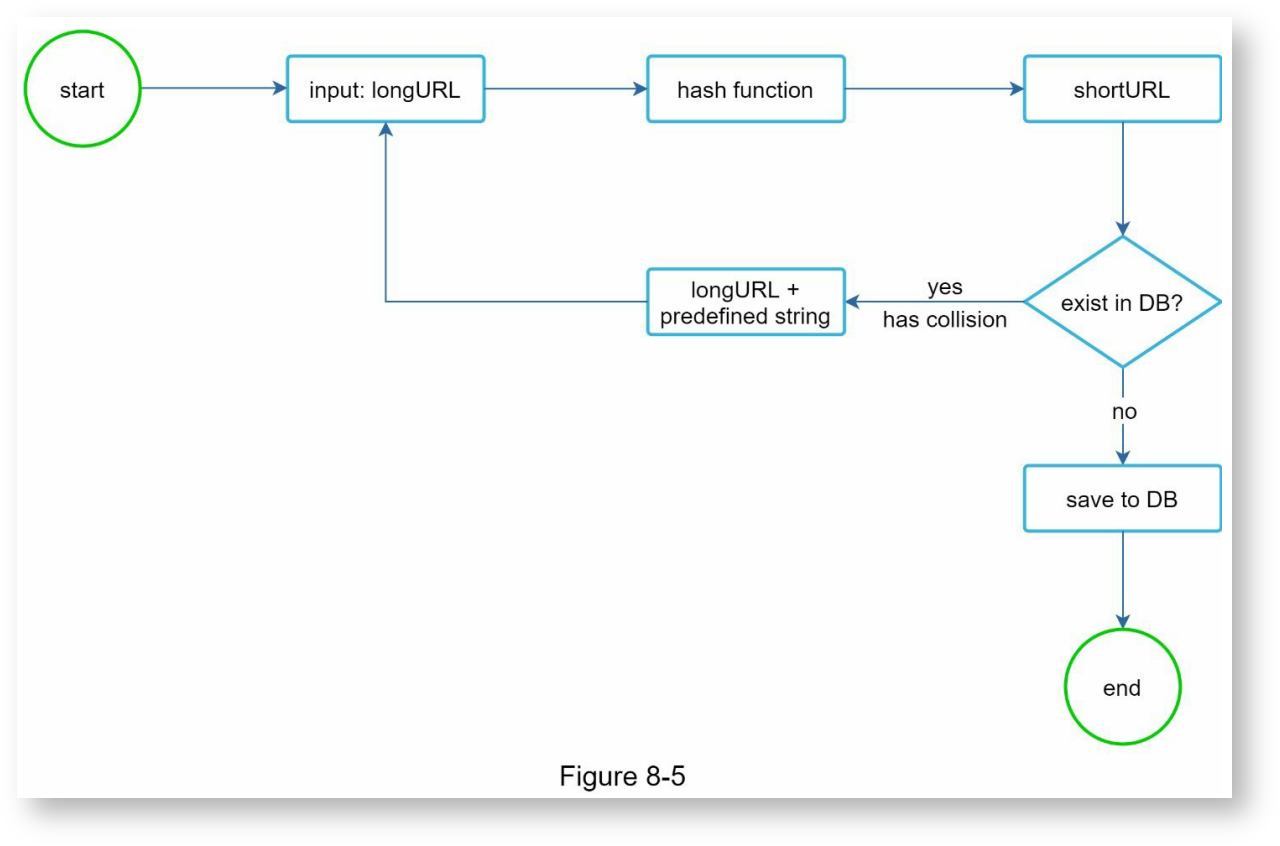
由于是在原来的网址上加上了0次或若干次预定义的字符串再生成短地址,所以在通过短地址拿到长地址时,要将长地址结尾的所有预定义字符串删除,这里可以将预定义字符串设置成在合法URL不可能出现的字符,避免误删URL中的合法字符,参考56 _ 算法实战(五):如何用学过的数据结构和算法实现一个短网址系统? · 语雀
这种方式在每次生成短网址时都需要查询数据库以判断是否哈希冲突,对服务器的负载压力较大。通过使用布隆过滤器可降低服务器的查询压力。布隆过滤器用于快速判断某个元素是否在一个给定的集合里,参考布隆过滤器 - 维基百科,自由的百科全书。
Base62转换
因为总共有62个可用字符,那么按顺序排列这62个字符,并且从0开始分别赋予权值,就可以用这62个字符来表示数字,等效于62进制,比如按0~9, a~z, A~Z的顺序排序,各个字符的权值分别是:0-0, ..., 9-9, 10-a, 11-b, ..., 35-z, 36-A, ..., 61-Z。
给定一个数字,将其转换成对应的62进制表示,就可以实现压缩,比如给定11157,转换成对应的62进制是2TX,这就实现了长度压缩。
两种算法对比
| 哈希+冲突检测 | Base62转换 |
|---|---|
| 固定长度 | 长度不固定,随输入递增 |
| 不需要唯一ID生成器 | 需要唯一ID生成器 |
| 存在冲突,必须解决冲突 | 不存在冲突,因为ID不会冲突 |
| 无法猜测下一个可用的短网址,因为哈希是随机的 | 很容易猜测出下一个可用的短网址,因为ID总是按1自增,存在安全隐患。 |
深入网址压缩设计
这里使用base62转换的方式进行网址压缩,整个流程图如下面所示:
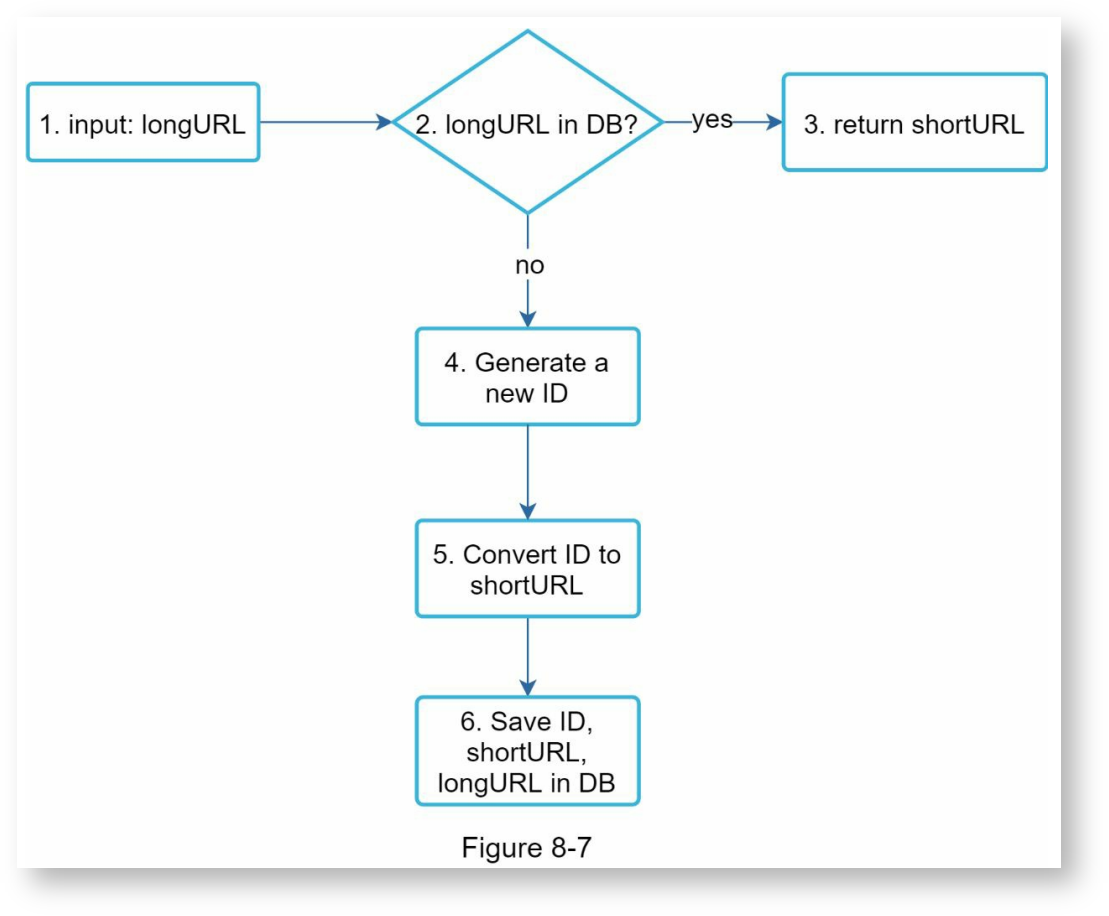
步骤:
- 输入长网址
- 检查长网址是否已存在,是则立刻返回对应的短网址
- 长网址在数据库中不存在,则为其生成一个新的ID,作为数据库的主键。在分布式环境下,这个ID一般由ID生成器生成。
- 对ID进行base62进制转换,生成短网址
- 数据库中插入一个新行,对应<ID, 短网址, 长网址>。
深入网址重定向设计
以下是网址重定向的设计,由于读多写少,这里使用了缓存来提高性能。
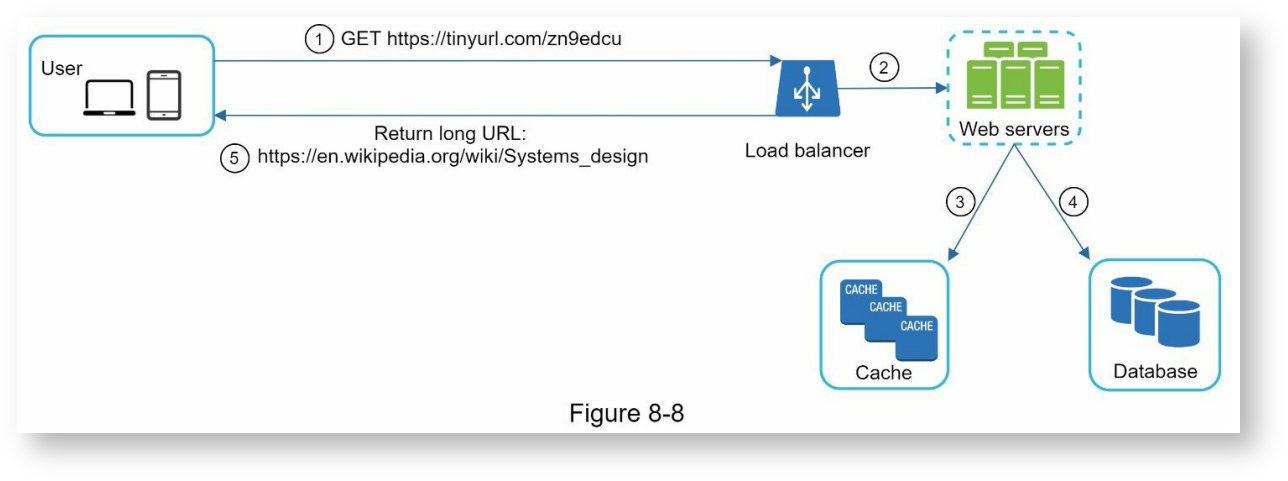
整个操作过程如下:
- 用户发送GET请求,对应短网址,比如
https://tinyurl.com/zn9edcu - 负载均匀器将请求转发到web服务器
- 如果缓存中有短网址记录,则直接返回结果
- 如果缓存中没有记录,则从数据库中查询,如果查询成功,则返回结果,并存入缓存,如果查询失败,则用户输入的短网址是无效的。
Step 4 - 总结
可供扩展延伸的讨论点:
- 限流。防止恶意用户发送超量请求,对服务器造成压力。
- web服务器扩展。采用无状态设计,以便于水平扩展。
- 数据库扩展。采用数据库复制和分片技术。
- 流量分析。分析链接的点击次数,时间段等信息。
- 可用性,一致性,可靠性。
- 是否可以实现一对多?一对多表示一条长网址可以生成多个短网址,这样方便做流量统计,比如发布到不同的网站时使用不同的短网址,就可以统计出来自各个网站的流量。