水平扩展中经常需要把请求/数据平均有效地分摊到不同的服务器上,一致性哈希算法可用于实现该功能。
rehashing问题
考虑有n台缓存服务器,需要把key-value类型的数据均匀地存储到这n台服务器上。一种常见的做法是先计算key的哈希值,然后用哈希值对n求余数来确定value存储在哪台服务器上。以下是一个示例,这个示例包含4台服务器和8个要存储的key,通过对key求哈希值,再将哈希值对4取余数可即可确定对应的服务器编号。
| key | hash | hash%4 |
|---|---|---|
| key0 | 18358617 | 1 |
| key1 | 26143584 | 0 |
| key2 | 18131146 | 2 |
| key3 | 35863496 | 0 |
| key4 | 34085809 | 1 |
| key5 | 27581703 | 3 |
| key6 | 38164978 | 1 |
| key7 | 22530351 | 3 |
要取出key对应的value时,按同样的方式计算一次即可确定服务器的编号。
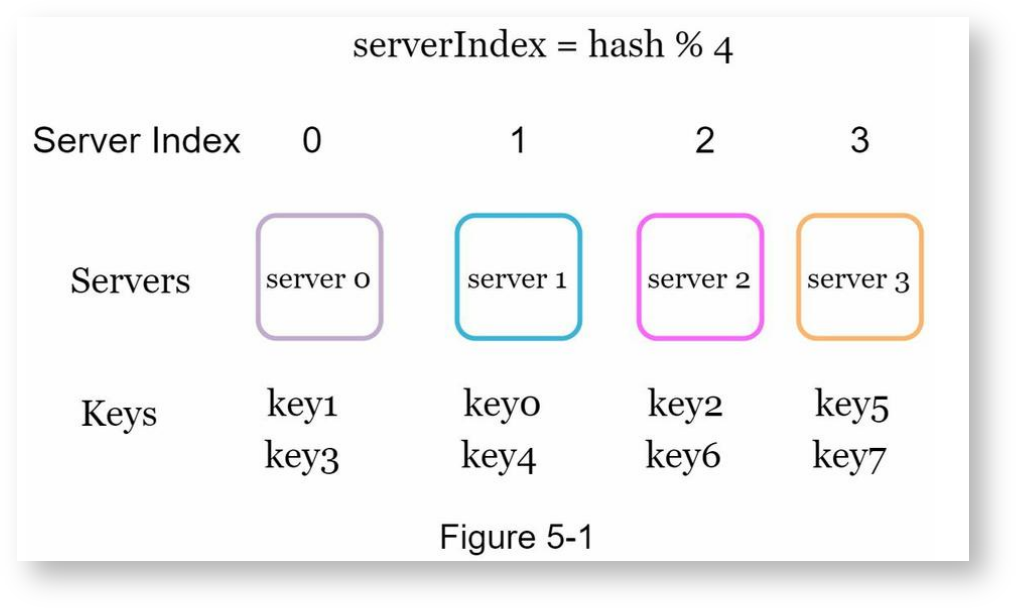
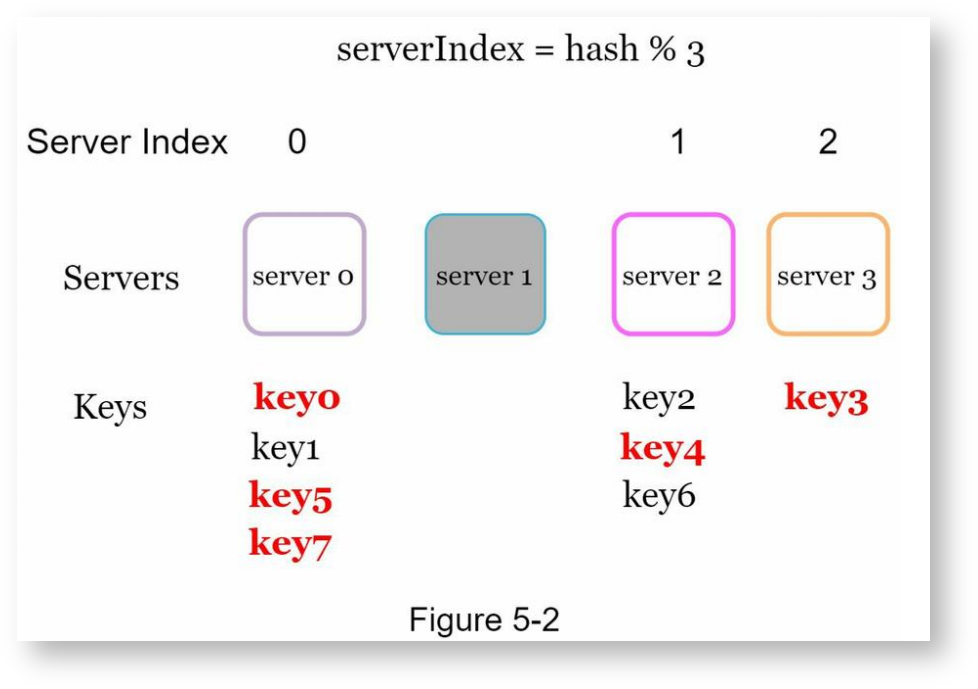
当服务器数量固定,且哈希分布均匀时,上面的方式没有问题。但当需要动态添加或删除服务器时,上面的方式就出现问题了,比如有一台服务器掉线、服务器数量变为3时,按同样的方式计算key的哈希,再对3取余,计算出来的服务器编号基本上是错误的,如下:
| key | hash | hash%4 |
|---|---|---|
| key0 | 18358617 | 0 |
| key1 | 26143584 | 0 |
| key2 | 18131146 | 1 |
| key3 | 35863496 | 2 |
| key4 | 34085809 | 1 |
| key5 | 27581703 | 0 |
| key6 | 38164978 | 1 |
| key7 | 22530351 | 0 |
一致性哈希
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n 个关键字重新映射,其中K是关键字的数量,n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。——维基百科
通俗地说,通过一致性哈希将key平均分布到n台服务器上,如果某个服务器出现故障,则只需要调整映射到这个服务器上的key,其他服务器上的key无需处理。
哈希空间与哈希环
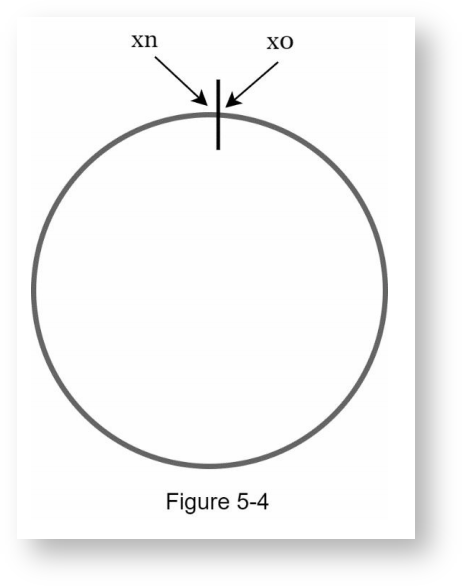
以SHA-1哈希算法为例,它的输出范围是0~2160-1,也就是哈希空间是0~2160-1,把首尾连接起来,就构成了哈希环。
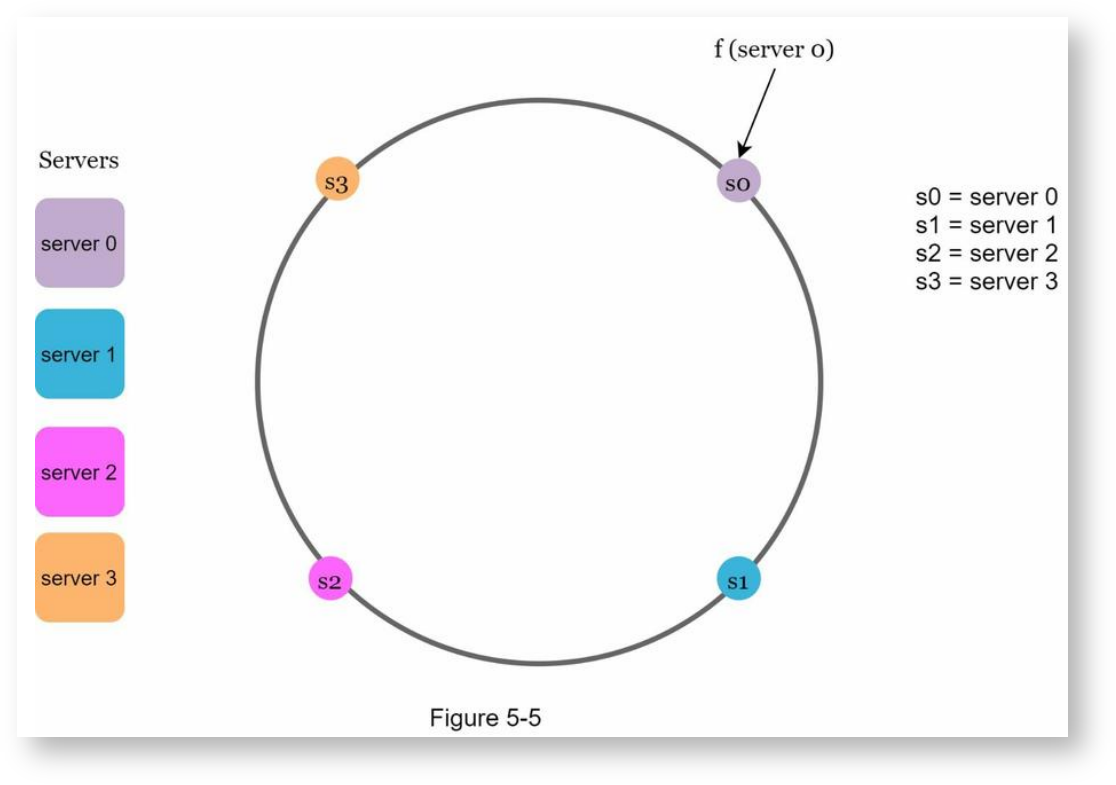
计算服务器哈希值
用相同的哈希算法对服务器计算哈希值,哈希的对象可以是服务器编号、IP地址或名称等,将计算出的哈希值映射到哈希环上:
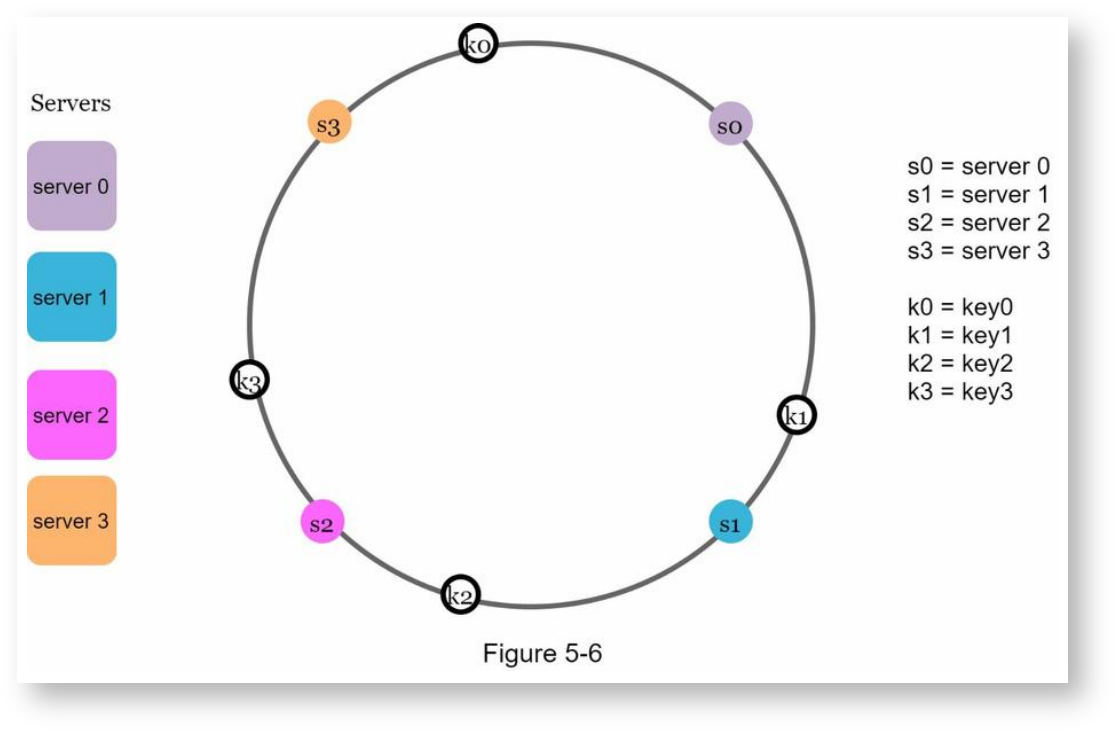
计算key的哈希值
用相同的算法计算各个key的哈希值,也放映射到哈希环上:
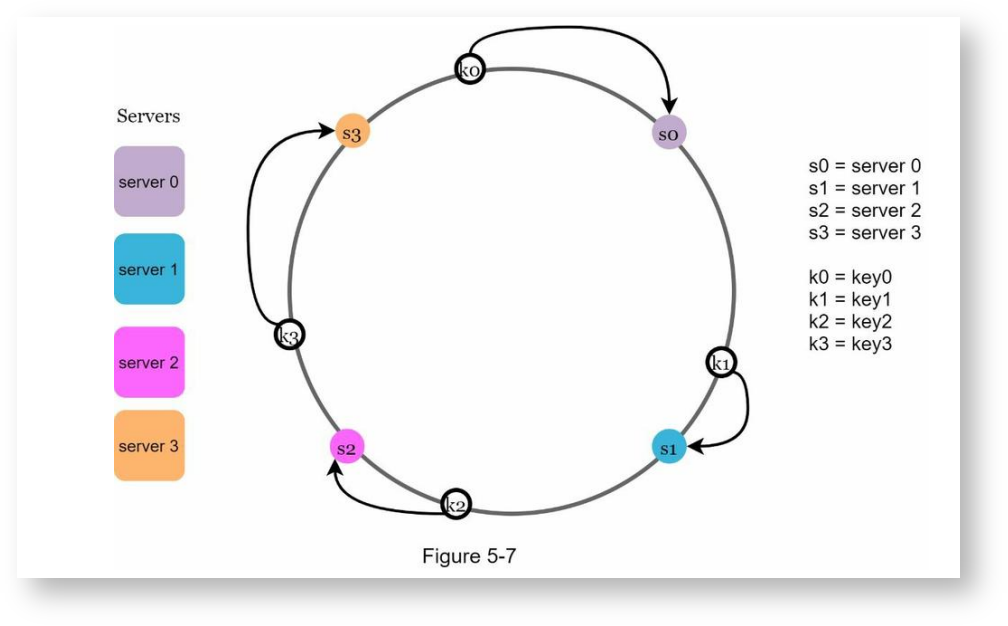
确定key存储在哪个服务器上
在哈希环上进行顺时针查找,用离key最近的服务器来存储key,如下:
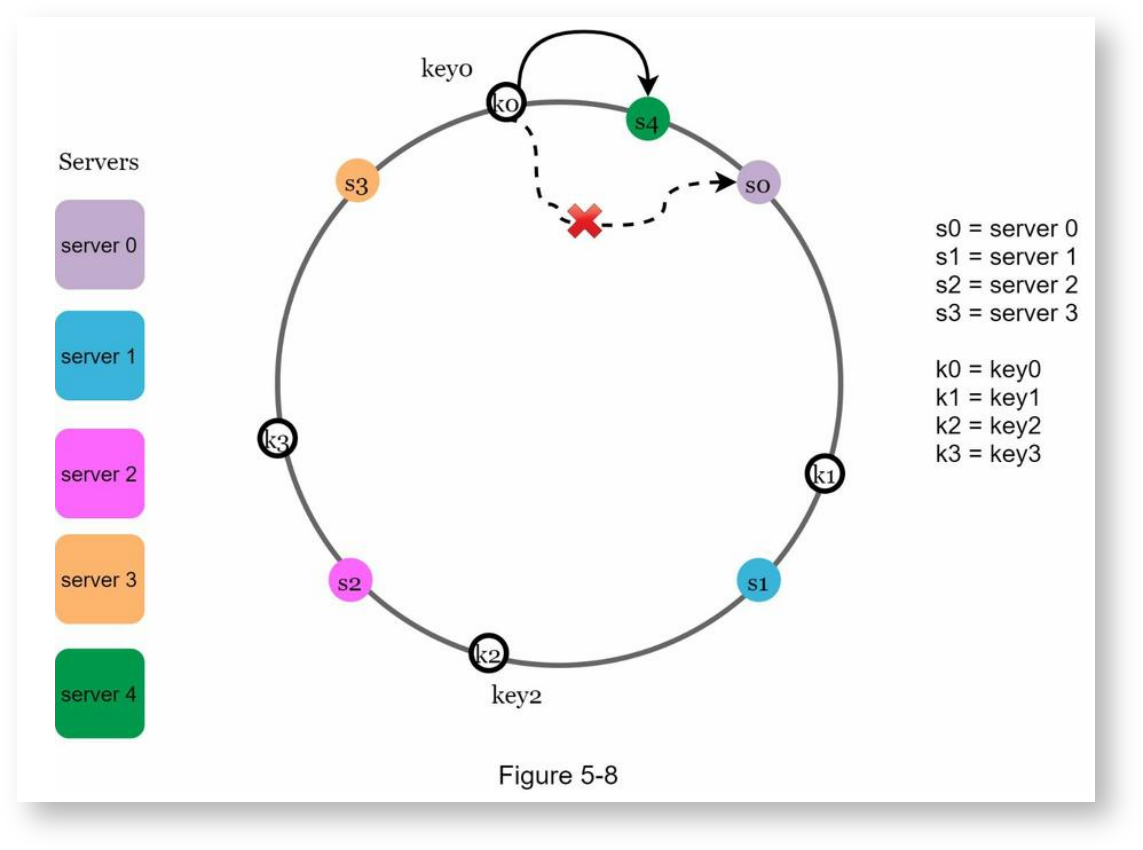
添加服务器
当添加服务器时,用同样的方式计算新服务器的哈希值,再把哈希值映射到哈希环上,然后调整受影响的key。具体的,从新服务器的哈希值逆时针往前找,直到找到前一个服务器,然后把这个区间内的key都重新映射到新服务器上,其他的key不需要处理,如下,这里以服务器4作为新添加的服务器来举例:
删除服务器
当删除服务器时,也用逆时钟查找的方式,将被删除的服务器和上一个服务器区间内的所有key重新映射到下一个服务器上,这里以删除服务器1举例:
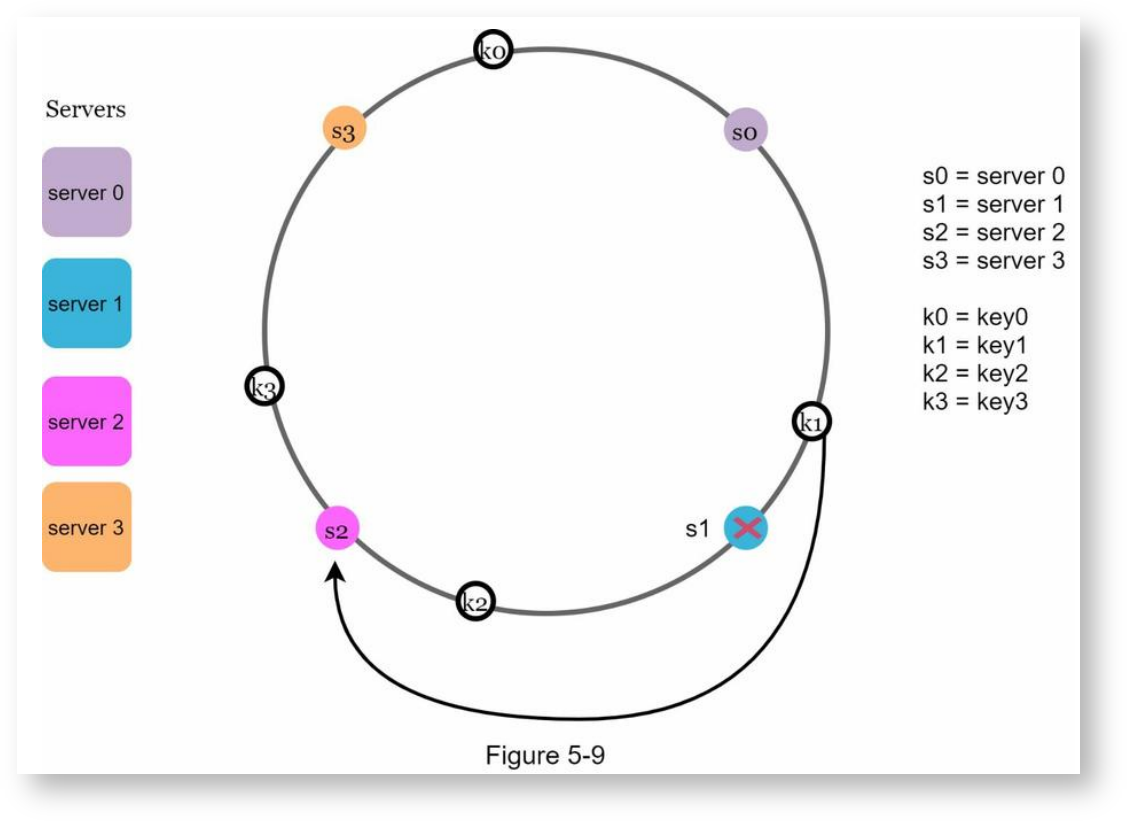
基本方法描述及问题点
上面的方式可总结为以下两点:
- 服务器和keys使用相同的哈希算法映射到哈希环上
- 在确定key对应的服务器时,只需要沿着key往顺时钟方向查找,找到的第一个服务器就是key对应的服务器。
这种方式存在的问题是哈希环上每个服务器占用的区间大小不可能一样大,也就意味着有的服务器可以接受更多的key,则有点只能接收更小的key,像下面这样:
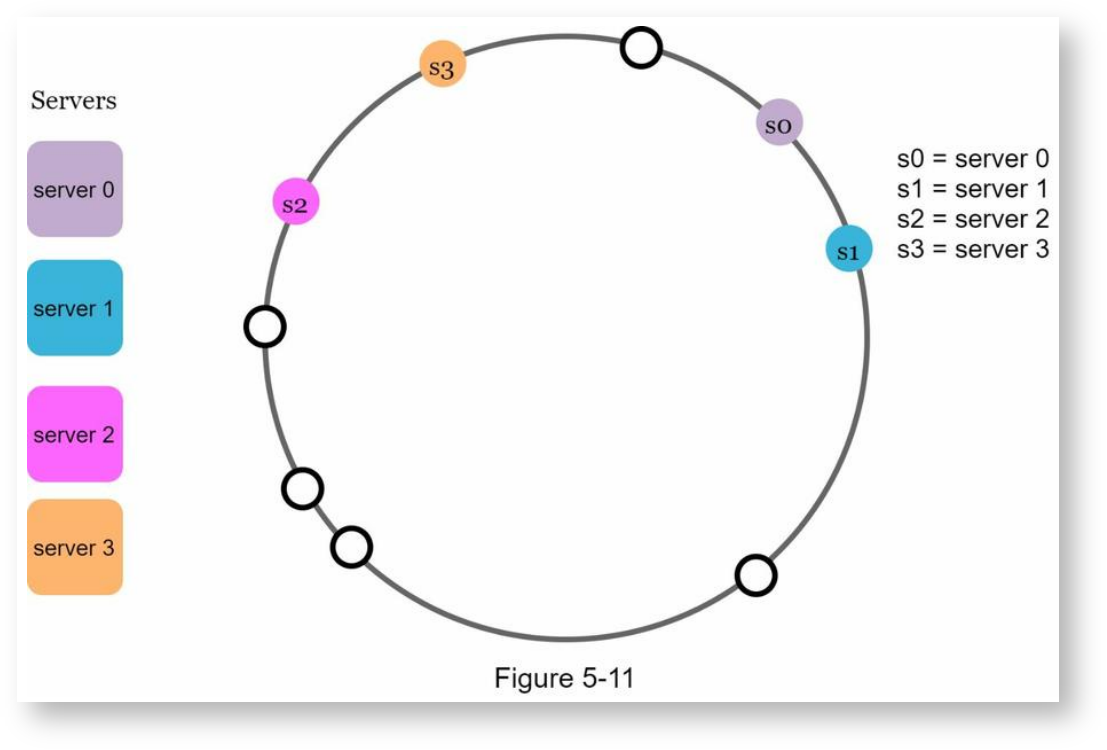
上面的示例中,大部分key都会落在服务器2上,服务器0、1、3只存储了少量的key。
使用虚拟结点可以解决上面的问题。
虚拟结点
用虚拟的结点来代表服务器,一个服务器可以有多个虚拟结点,如下:
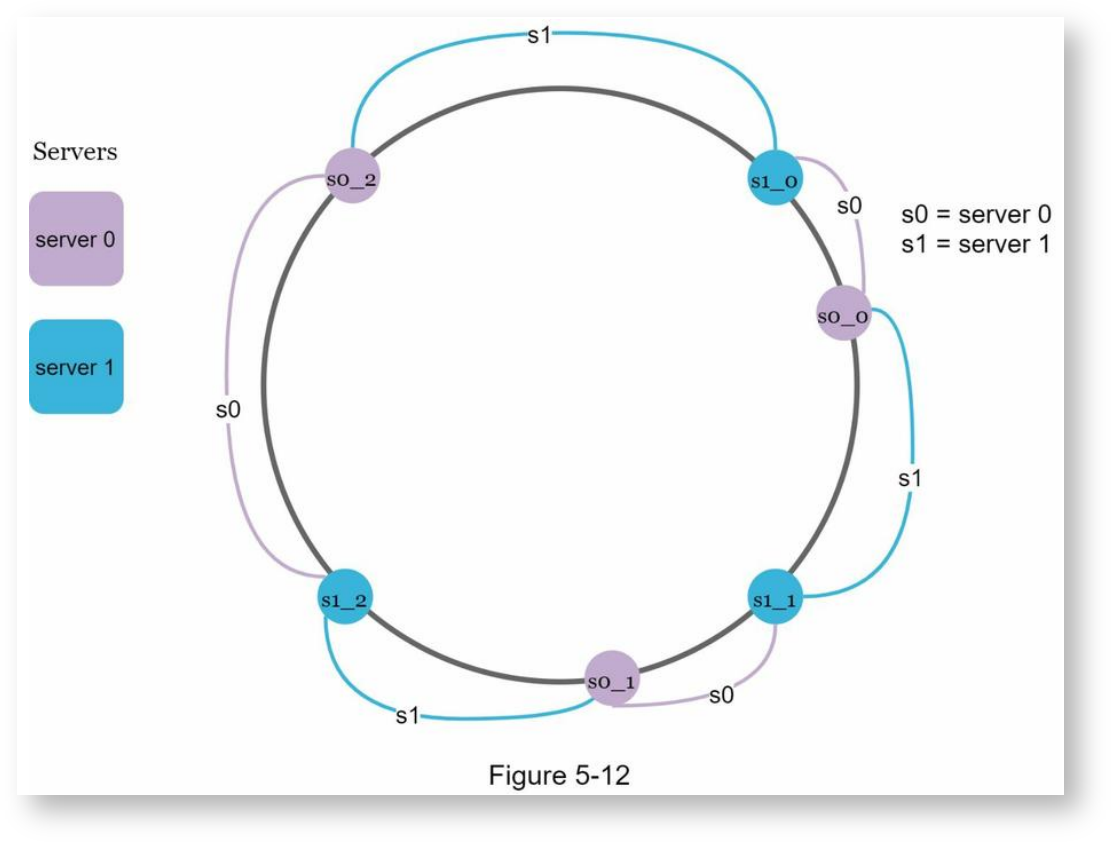
上面的示例中:s0_0, s0_1, s0_2都代表服务器1,s1_0, s1_1, s1_2都代表服务器2。
通过虚拟结点,可以使一台服务器管控多个区间,通过选取合适的虚拟结点,就可以使每个服务器管控的区间都比较均匀。而且,虚拟结点越多,则每个服务器管控的key分布也就越均匀,并且在增加或删除服务器时,受影响的key数量也就越少。
虚拟结点本质就是增加了一层映射,体现了“计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决”的设计哲学。
总结
哈希一致性有助于处理以下问题:
- 在增加或删除服务器时,将受影响的key数目降到最低
- 有利于系统水平扩展,因为数据是平均分布的
- 降低热点key问题的影响。使用哈希一致性可将数据分布得相对平均,降低单个热点key对服务器造成的数据压力。