单服务器模型
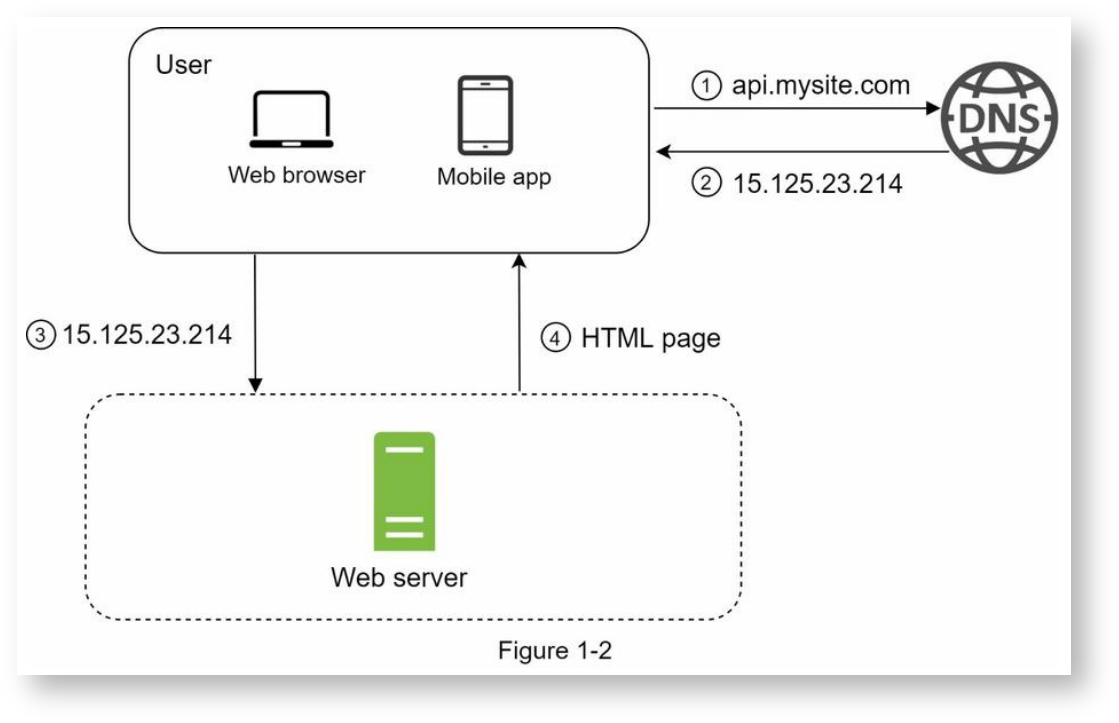
重点:只有一台Web服务器,所有的访问和数据处理都在这台服务器上处理。
用户访问过程:
1. 浏览器或客户端输入访问URL,一般是以域名形式进行访问。
2. DNS域名解析,拿到服务器的IP地址。
3. 根据IP地址访问服务器。
4. 服务器返回结果。
单服务器带数据库模型
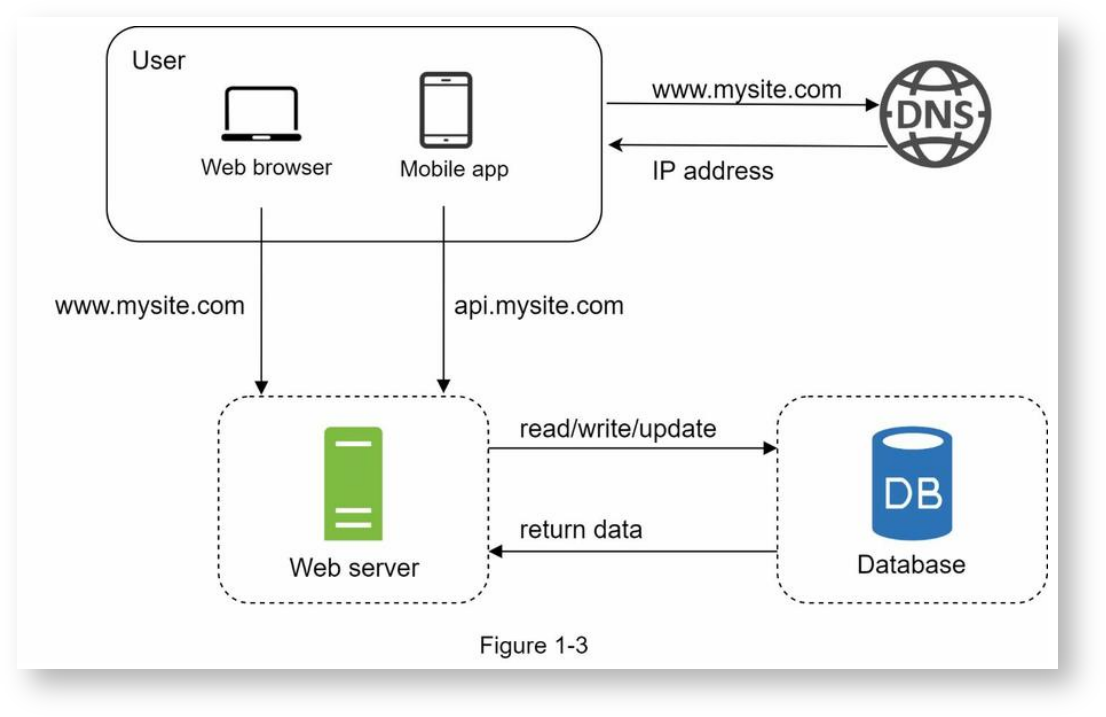
重点:增加了一台单独的数据库服务器,用于缓解Web服务器上数据访问压力。一般使用关系型数据库,如MySQL。
关于垂直扩展与水平扩展
垂直扩展指增加单个服务器的处理能力,比如堆内存,堆CPU核心,堆SSD等。水平扩展指增加更多的服务器,通过负载均衡的手段将流量分布到各个服务器上,从而提高并发能力。
流量较小时,垂直扩展效果显著,且操作简单。但随着流量的增加,垂直扩展将很快触顶,因为硬件的机能是有上限的,不能无限叠加,这时只能寻求水平扩展。并且垂直扩展不具备容错(failover)和冗余(redundancy)能力,如果服务器挂了,整个系统也就不可用了。
增加负载均衡
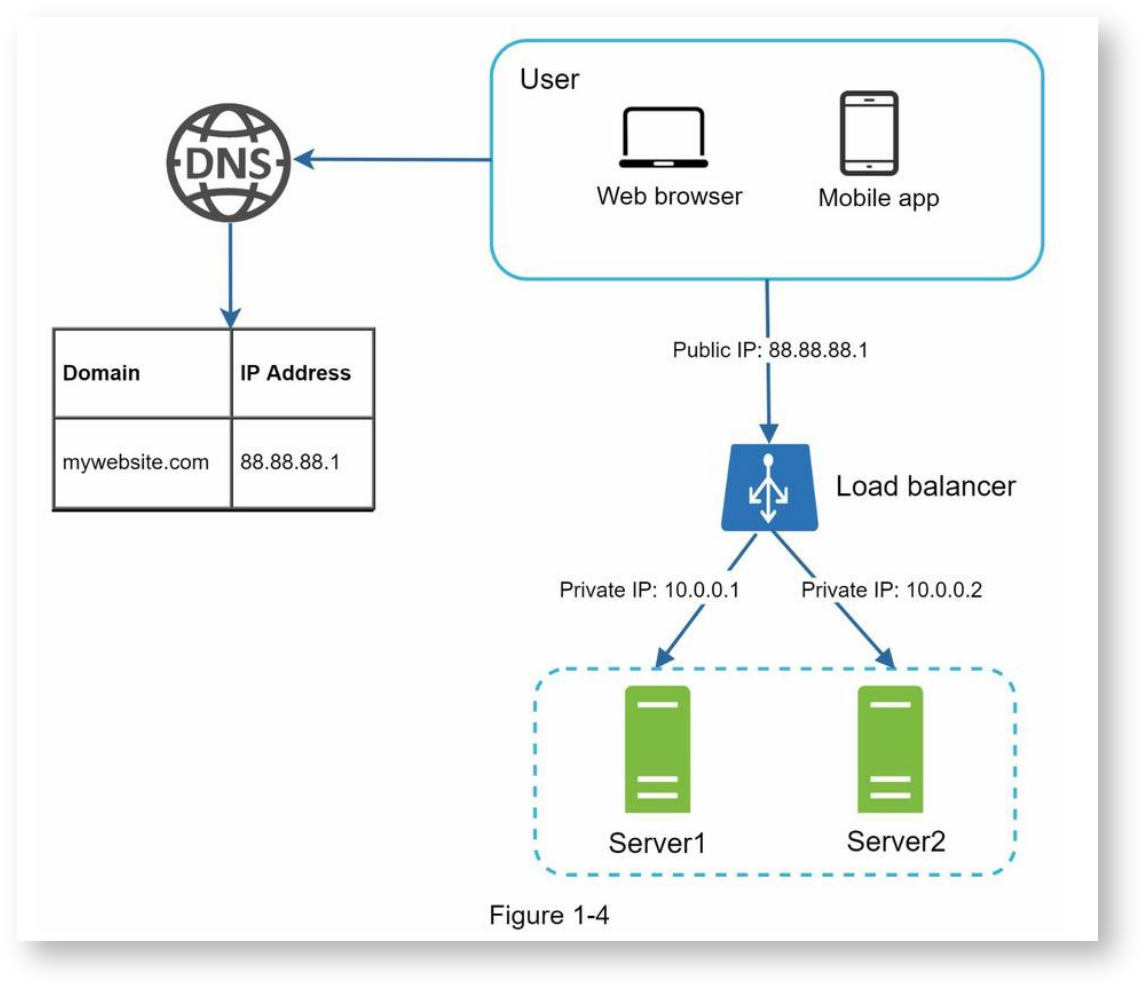
重点:通过负载均衡将流量平均分布到一组服务器上,降低单个服务器的压力,并且使系统具备了容错能力。当两个服务器中的任何一个挂掉时,流量可以转发到另一台上,由此提高了可用性。
此方案下服务器一般位于内网中,需要使用反向代理才能让外面的设备访问到。
增加冗余数据库
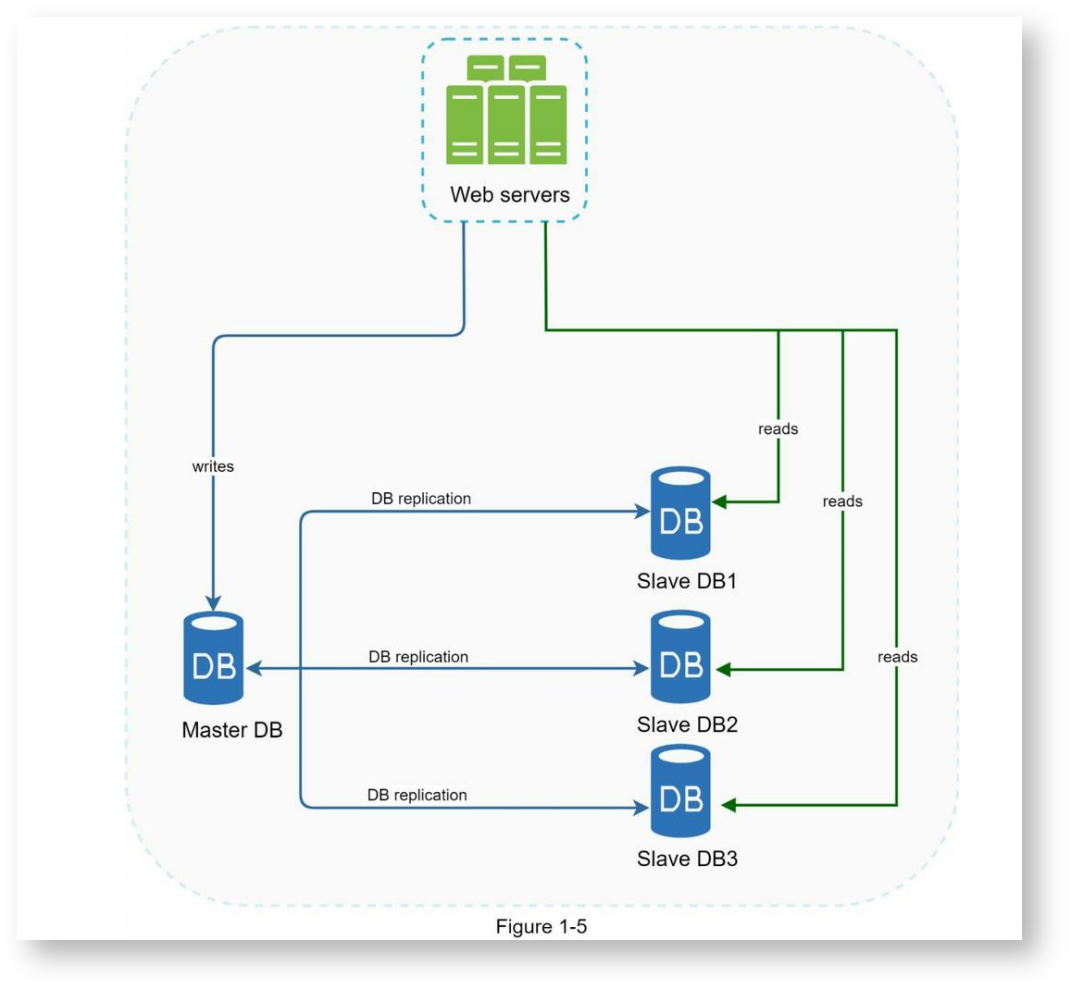
重点:使用数据库复制(Database Replication)技术,增加数据层的并发能力和容错能力,提高可用性。
通常有一个主数据库,提供只写操作,有多个从数据库,提供只读操作。主从数据库之间通过数据库复制技术保证数据同步。
所有对数据的增加、删除、修改操作都发生在主数据库上,从数据库只负责同步主数据库的内容,然后提供查询功能,由于读的频率一般比写高很多,所以从数据库的数量一般要比主数据库多。
为提高可用性,当所有的从数据库都挂掉时,主数据库也可以临时提供查询功能,当主数据库挂掉时,可以将某个从数据库临时提升成主数据库。
阶段设计一
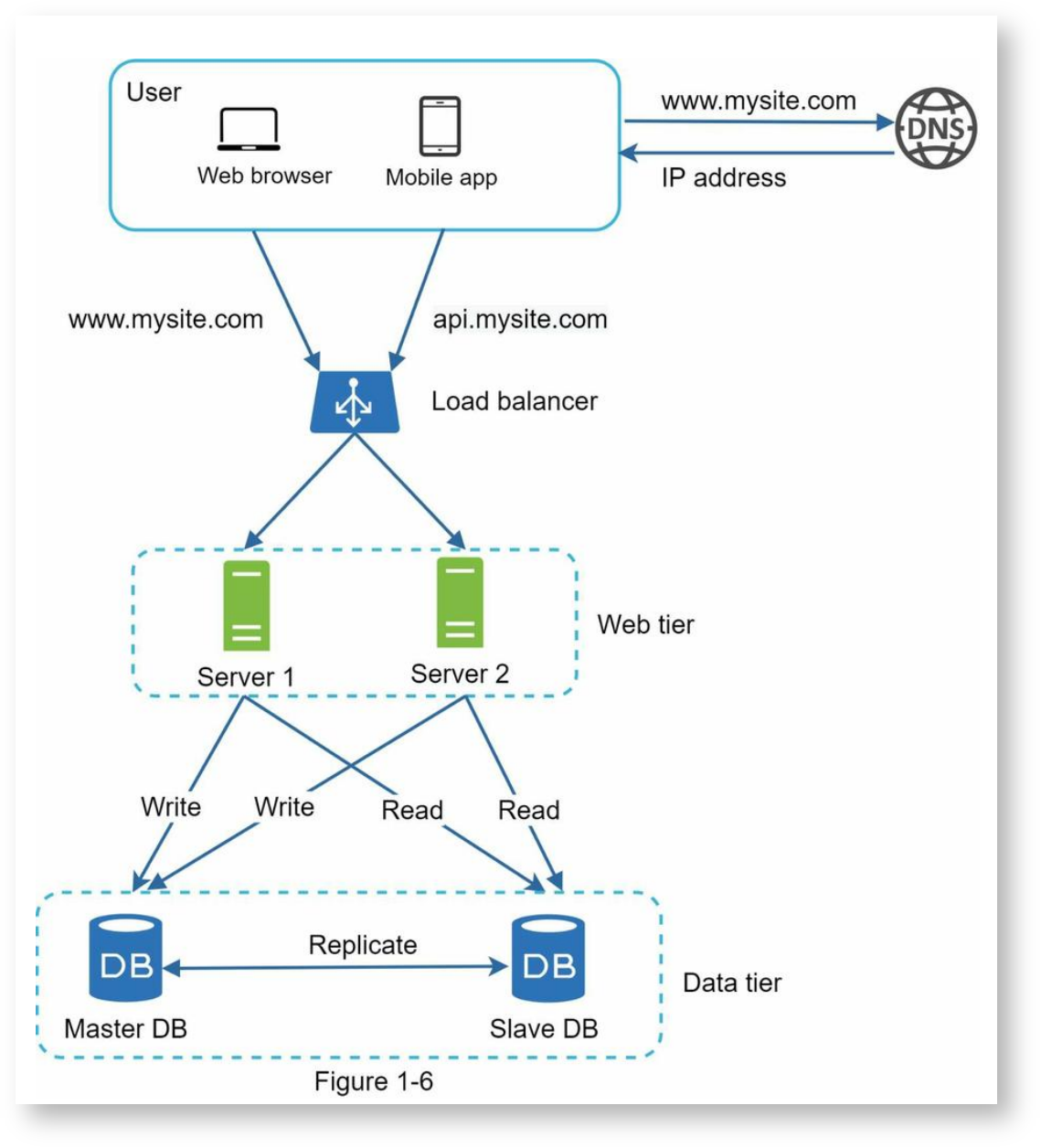
重点:增加了负载均衡和数据库复制。
增加缓存
缓存用于临时存储数据,避免每次访问都从数据库中查询。由于缓存往往速度比较快,对于一些使用,或是查询代价较高的数据,可以存储在缓存中,以提高响应速度。
缓存层
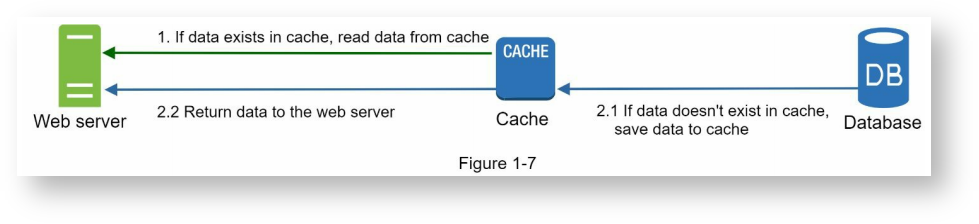
收到响应后,Web服务器首先查询缓存,看有没有对应的结果。如果有,则把缓存中的结果发给客户。如果没有,则查询数据库,并将查询的结果保存到缓存中,这样下次访问时就可以从缓存中取数据。
使用缓存要考虑以下几点:
1. 使用场景。缓存适用于读多写少的场景,并且由于缓存一般存储在内存里,关机时会丢失,所以不要用缓存要保存重要数据。
2. 过期策略。删除过期数据,以节省内存。当过期时间设置得较小时,数据会被频繁加载,当过期时间设置得较大时,数据会堆积。