Hello, World!
#include <stdio.h>
int main()
{
printf("hello, world\n");
}
这个程序实现的效果是在终端命令行输出一行"hello, world",编译及执行这个程序:
root@DESKTOP-38B6GK1:~/C# gcc helloworld.c -o helloworld root@DESKTOP-38B6GK1:~/C# ./helloworld hello, world
sum = a + b
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int sum = a + b;
printf("sum is %d\n", sum);
}
这个程序先定义了两个变量 a 和 b ,值分别为 1 和 2 ,再定义变量sum并将a加b的和赋值给sum,最后输出sum的值,编译及执行这个程序:
root@DESKTOP-38B6GK1:~/C# gcc sum.c -o sum root@DESKTOP-38B6GK1:~/C# ./sum sum is 3
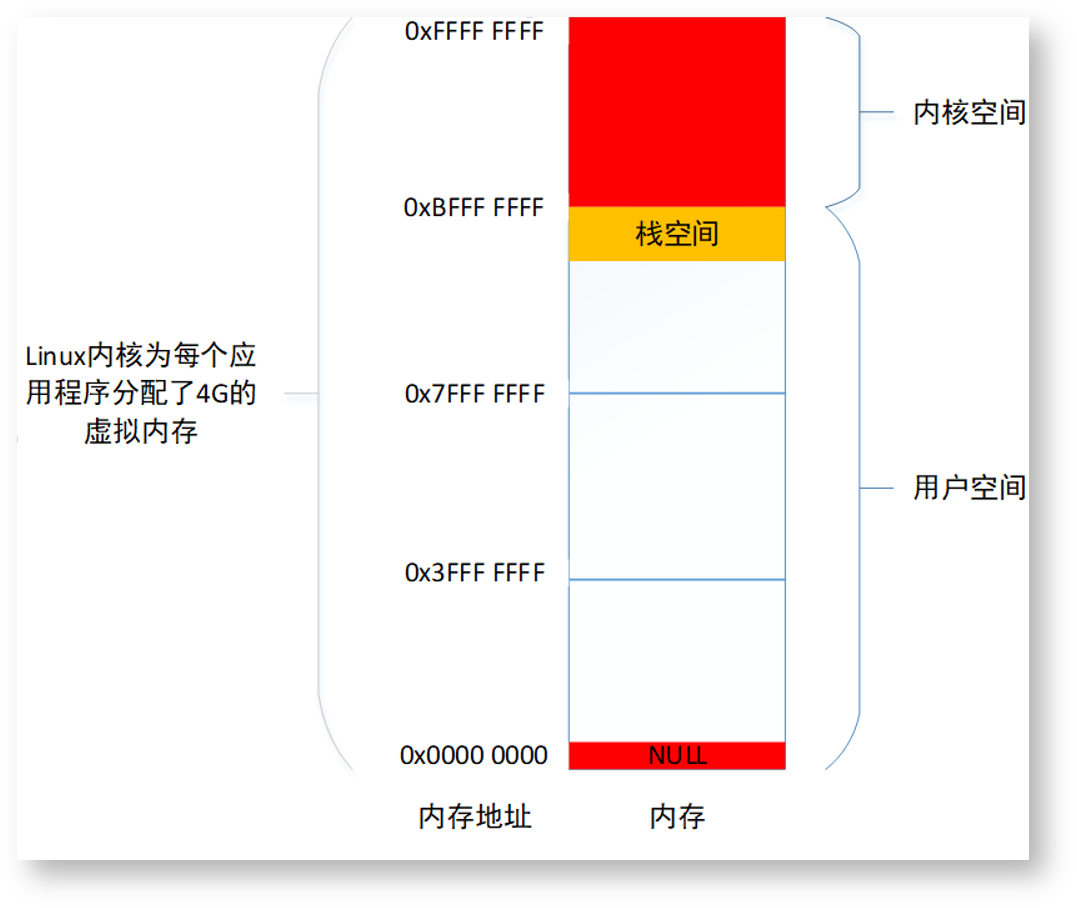
内存图
下面是在32位Linux系统下,一个进程的虚拟内存分布图,当前只需要注意以下几点:
- 32位系统下,进程的虚拟内存大小为4GB,也就是2^32Byte,范围为0x00000000~0xFFFFFFFF。
- 将这4GB虚拟内存进行分类,其中低3GB内存归进程使用,称为用户空间,范围是0x0000000~0xBFFFFFFF,最高的1GB归内核使用,称为内核空间,范围是0xC0000000~0xFFFFFFFF。
- 进程的所有内容都必须存放在这4GB的内存里,比如程序的二进制代码,以及运行过程中需要使用的数据。
- 靠近0x00000000地址的一小部分空间进程不能使用,比如典型的NULL地址,如果往这个地址存放数据,则程序会崩溃。
- 靠近3GB用户空间顶端的一小段内存称为栈空间,这里用于存放程序的局部变量,比如上面sum.c中定义的变量a, b, sum。
取地址与解地址
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int sum = a + b;
printf("a is %d\n", a);
printf("b is %d\n", b);
printf("sum is %d\n", sum);
// 取地址
printf("address of a is %p\n", &a);
printf("address of b is %p\n", &b);
printf("address of sum is %p\n", &sum);
// 解地址
printf("a is %d\n", *(&a));
printf("b is %d\n", *(&b));
printf("sum is %d\n", *(&sum));
// 以此类推...
printf("address of a is %p\n", &(*(&a)));
}
编译运行效果:todo
这个程序先输出a, b, sum的值,再通过取地址符&获取到它们的内存地址,可以看到它们的地址的确位于靠近3G内存顶部的栈空间。拿到地址后,还可以通过解地址符*再解出这个地址对应的值。取地址和解地址的操作可以相互抵消。
五则运算
#include <stdio.h>
int main()
{
int i = 20;
int j = 3;
printf("%d\n", i + j);
printf("%d\n", i - j);
printf("%d\n", i * j);
printf("%d\n", i / j); // 整除
printf("%d\n", i % j); // 取模
}
上面是整数的五则运算,注意整数的除法执行的是整除操作,结果仍是整数,而%则是取模操作,用于求余数,编译运行效果如下:
root@DESKTOP-38B6GK1:~/C# gcc caculate.c -o caculate root@DESKTOP-38B6GK1:~/C# ./caculate 23 17 60 6 2
注释
注释是程序中的说明语句,用于解释某些语句的作用,其目的是为了方便阅读程序。注释不参与C语言的编译,任何注释都会在编译过程中都会被忽略。
注释有两种形式,分别是单行注释和多行注释,单行注释的形式是//注释内容,多行注释的形式是/*注释内容*/,如下:
#include <stdio.h>
int main() {
// 这是单行注释
/* 这是多行注释
可以跨行 */
}
良好的注释可以提高代码的可读性,在编写大型项目的代码时,往往要遵循一定的规范对代码进行注释,以使代码更加容易理解和维护,这里有一些供参考的注释规范。
关键字
关健字又称保留字,是预留给C语言本身使用的名词,在C语言中不可以用作其他用途,比如,不可以用关键字给变量命名,C89规定的关键字共有32个。根据关键字的作用分为四类:
- 数据类型关键字(12个)
int, char, short, long, float, double, signed, struct, unsigned, union, enum, void - 控制语句关键字(12个)
break, case, continue, default, do, else, for, goto, if, return, switch, while - 存储类型关键字(4个)
auto, extern, register, static - 其他关键字(4个)
const, sizeof, typedef, volatile
数据类型
数据类型用于指定一块内存的类型和大小,比如可以用于定义具有不同类型的变量,以存储不同范围的数据,C语言的数据类型可以分为以下四类:
- 基本数据类型:类似int,char,float,double这样的不可再划分的数据类型
- 结合数据类型:通过结合另一个数据类型构造出的类型,有数组和指针两种类型
- 构造数据类型:自定义的类型,包括结构体,联合体,枚举类型
- 空类型:void
变量
变量代表一段有名字的内存空间,定义变量的方式是 数据类型 + 名称,比如int i 定义了一个整型变量 i,它的类型是int,一般存储在程序的栈空间,占用大小是4字节。
标识符
用来表示程序中使用的变量名、数组名、函数名和其它由用户自定义的数据类型的名称。定义标识符的时候要注意以下几点:
- 只能由英文字母、数字和下划线构成,长度为1~32。
- 必须以字母或下划线“_”开头。
- 标识符严格区分大小写字母。
- 不能以C语言的关键字作为标识符。
- 标识符选用应尽量做到“见名知意”,即选用有含义的英文单词或缩写,如sum, name, max等。
运算符、操作数、表达式
运算符是可以对数据进行运算的符号,比如上面的五则运算,其中的+、-、*、/、%就是运算符。
运算符操作的对象称为操作数,运算符与操作数组合成表达式。表达式结尾没有分号,如果在表达式两边加上一个括号,那么表达式最终可以得到一个值,这是表达式与语句的区别。
程序错误
指程序出错的情况,程序的错误分为两类,一类是编译时错误,发生在程序编译期间,表示程序语法有问题,比如写错了关键字,或是某些语句有潜在的风险。另一类是运行时错误,这类错误表示程序语法没问题,可以通过编译,但程序逻辑有问题或是达不到预期的结果,比如执行除法运算时除数为0,或是原本要求执行乘法,但编码时写成了加法,导致结果不对。
这里重点说一下编译时错误,对于编译时的错误,可以分类两类,如下:
- Error
程序中有语法错误,编译不通过,不能生成可执行文件。 - Warning
程序中存在潜在的错误(比如printf未提供与占位符个数相等的参数),编译可以通过,可以生成执行文件。有些警告需要加-Wall选项才会提示Warning。