水平扩展中经常需要把请求/数据平均有效地分摊到不同的服务器上,一致性哈希算法可用于实现该功能。
rehashing问题
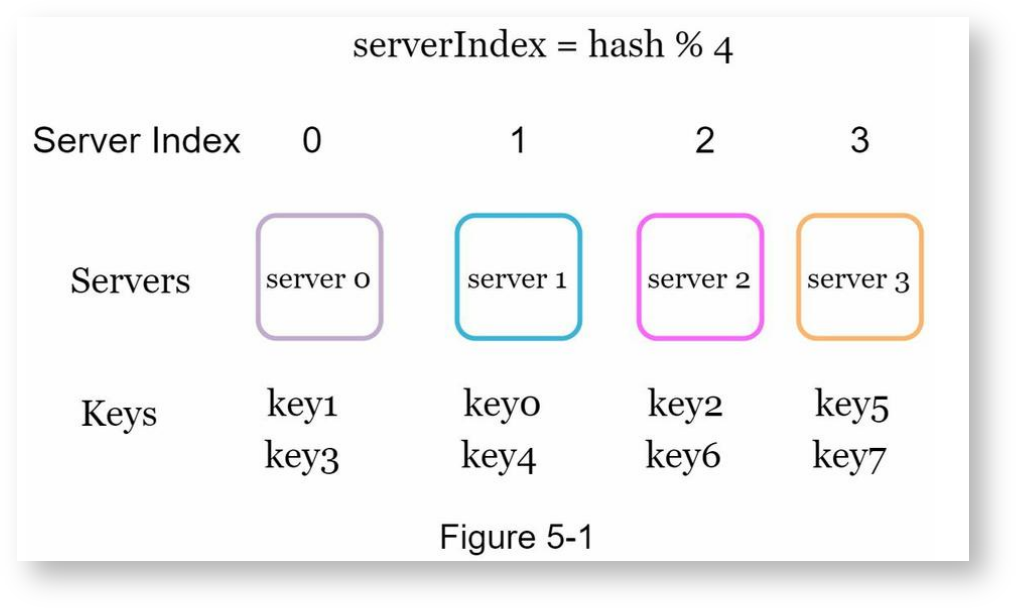
考虑有n台缓存服务器,需要把数据均匀地存储到这n台服务器上。一种常见的做法是先计算数据的哈希值,然后用哈希值对n求余数来确定存储在哪台服务器上。以下是一个示例,这个示例包含4台服务器和8个要存储的key,通过对key求哈希值,再将哈希值对4取余数可即可确定对应的服务器编号。
| key | hash | hash%4 |
|---|---|---|
| key0 | 18358617 | 1 |
| key1 | 26143584 | 0 |
| key2 | 18131146 | 2 |
| key3 | 35863496 | 0 |
| key4 | 34085809 | 1 |
| key5 | 27581703 | 3 |
| key6 | 38164978 | 1 |
| key7 | 22530351 | 3 |
要取出key时,按同样的方式计算一次即可确定服务器的编号。
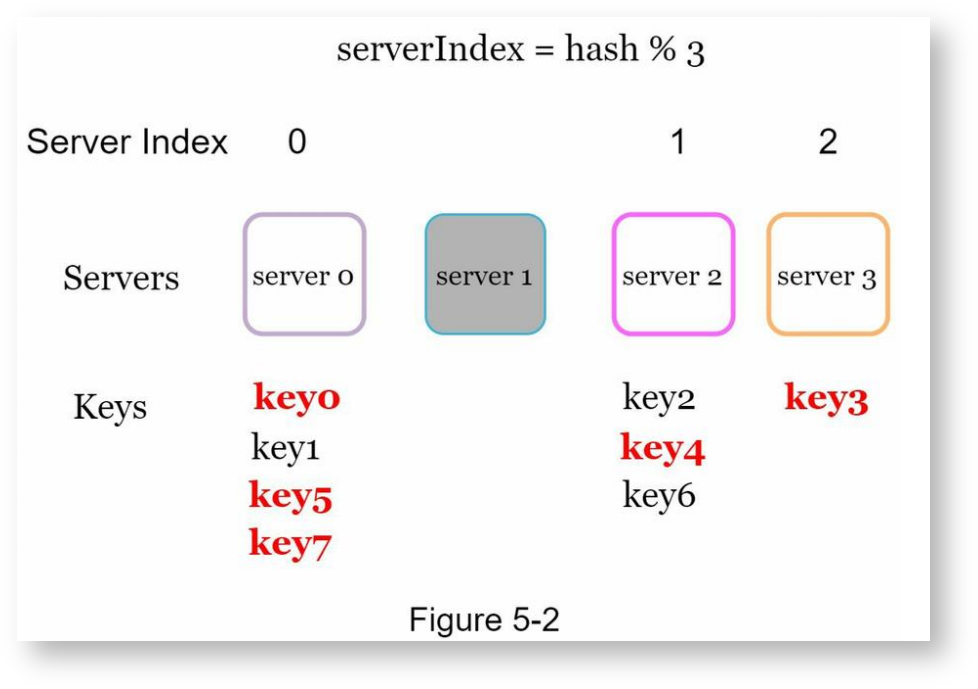
当服务器数量固定,且哈希分布均匀时,上面的方式没有问题。但当需要动态添加或删除服务器时,上面的方式就出现问题了,比如有一台服务器掉线、服务器数量变为3时,按同样的方式计算key的哈希,再对3取余,计算出来的服务器编号基本上是错误的,如下:
| key | hash | hash%4 |
|---|---|---|
| key0 | 18358617 | 0 |
| key1 | 26143584 | 0 |
| key2 | 18131146 | 1 |
| key3 | 35863496 | 2 |
| key4 | 34085809 | 1 |
| key5 | 27581703 | 0 |
| key6 | 38164978 | 1 |
| key7 | 22530351 | 0 |
一致性哈希
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对
个关键字重新映射,其中
是关键字的数量,
是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。——维基百科
通俗地说,通过一致性哈希将key平均分布到n台服务器上,如果某个服务器出现故障,则只需要调整映射到这个服务器上的key,其他服务器上的key无需处理。
哈希空间与哈希环
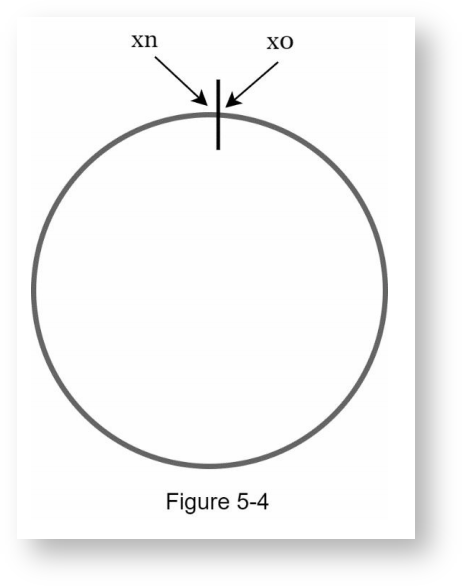
以SHA-1哈希算法为例,它的输出范围是0~2160-1,也就是哈希空间是0~2160-1,把首尾连接起来,就构成了哈希环。

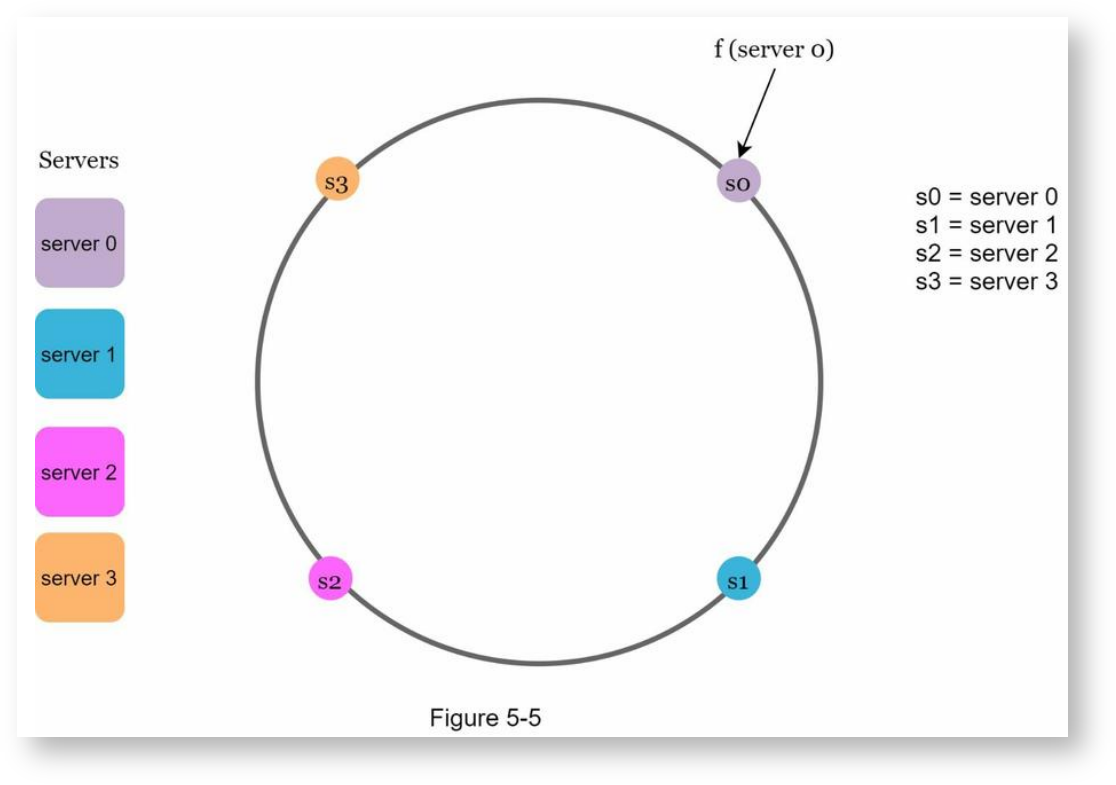
计算服务器哈希值
用相同的哈希算法对服务器计算哈希值,计算的依据可以是编号,IP地址,或是服务器名称等。将计算出的哈希值映射到哈希环上:
计算key的哈希值
用相同的算法计算各个key的哈希值,也放映射到哈希环上:
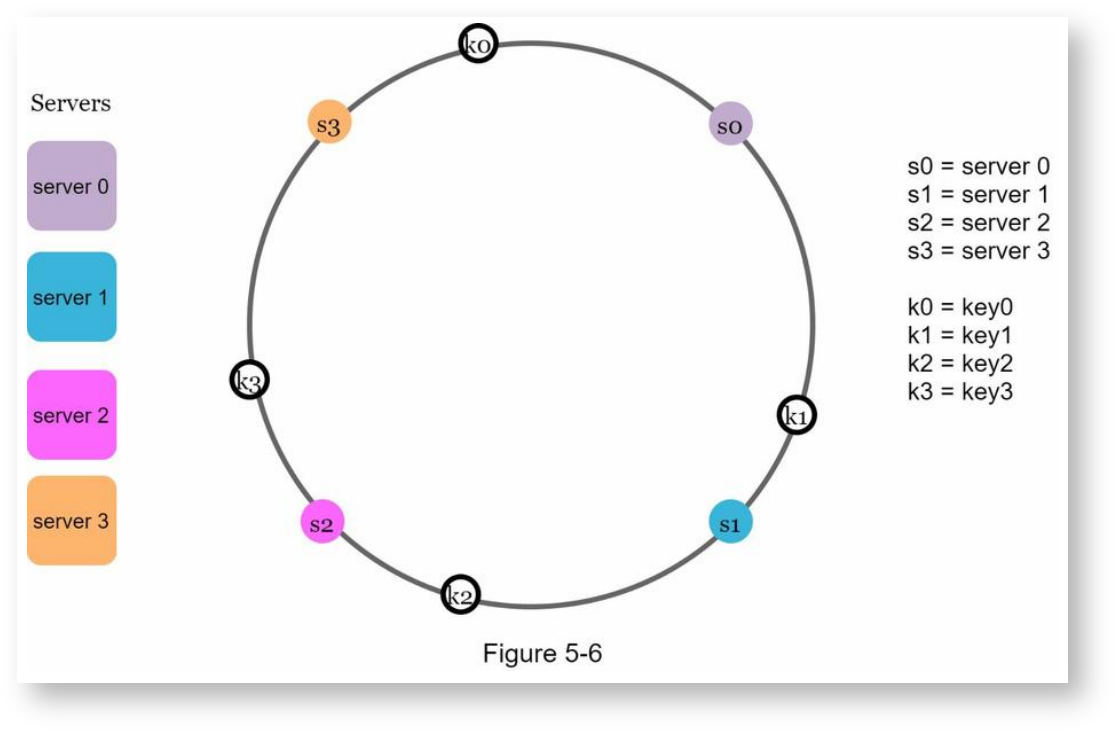
确定key存储在哪个服务器上
在哈希环上进行顺时针查找,用离key最近的服务器来存储key,如下:
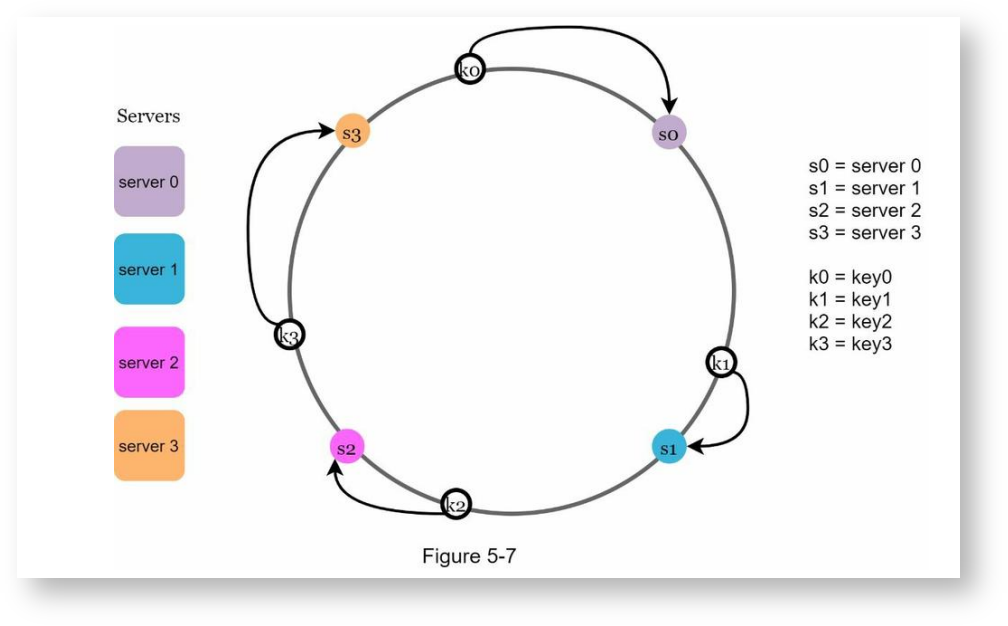
添加服务器
当添加服务器时,用同样的方式计算出新服务器的哈希值,再把哈希值映射到哈希环上,然后只调整受影响的key值。具体得,从新服务器的哈希值逆时针往前找,直到找到前一个服务器,然后把这个区间内的key都重新映射到新服务器上,其他的key不需要处理,如下,这里以服务器4作为新添加的服务器来举例:
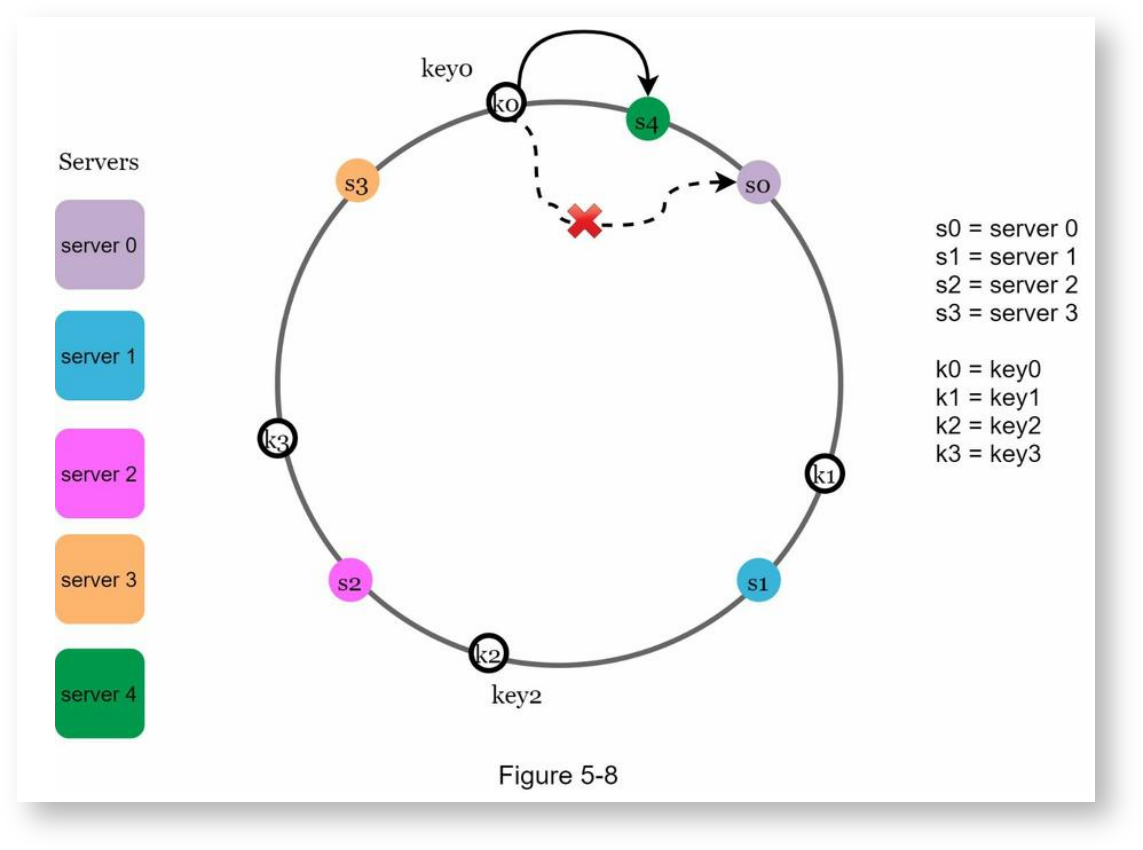
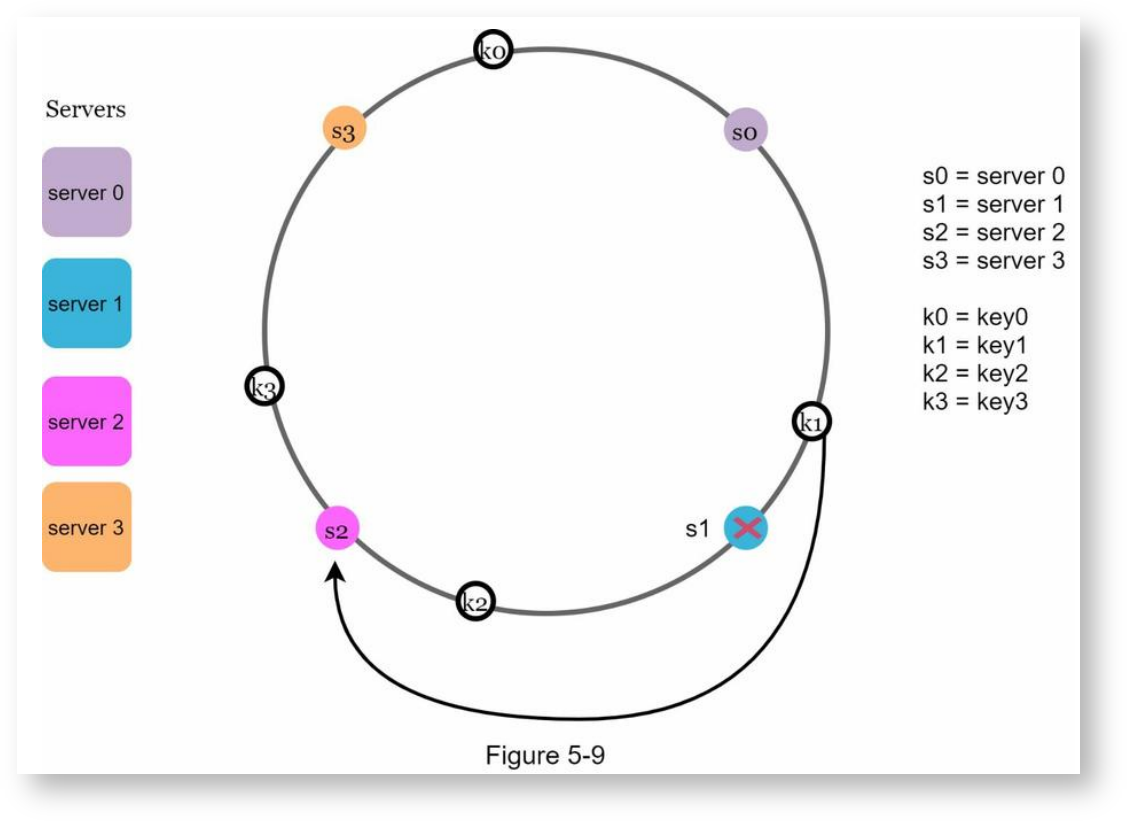
删除服务器
当删除服务器时,也用逆时钟查找的方式,将被删除的服务器和上一个服务器区间内的所有key重新映射到下一个服务器上,这里以删除服务器1举例: