补码与浮点数
整数的正负表示
计算机采用二进制表示数据,但是从数学意义上,使用二进制并不能表示负数。因为二进制每一位的权值都大于0。为了解决这个问题,人们在二进制数据上使用了符号位,通过符号位来表示数据的正负。符号位是数据的最高位,当这一位为0时,表示数据是正数,而符号位为1时,则表示这个数是负数。
以short类型为例,通过下面两个示意图,可以看出符号位的作用: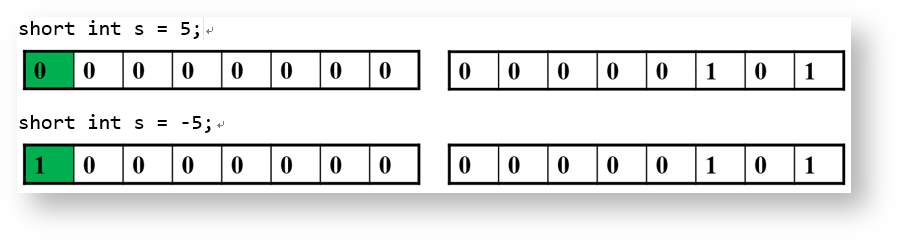
正是因为这些数据的最高位是符号位,所以又称之为有符号数,用signed修饰(无修饰是默认是signed)。
与有符号数对应的是无符号数。用unsigned修饰,无符号数的最高位仍然用来表示数值大小,不用于表示数据符号,所以如果某个存储单元存储的是无符号数,那么从这里面读出的数永远不可能是负数。
有符号数的存储
无论是整数还是浮点数,最终都需要以一定的形式存入内存。对于整数,由于它可以转化成二进制形式,所以在内存中存储对应的二进制就可以了,这点对unsigned类型是适合的,但是对有符号数signed类型,将有所不同。浮点数由于比较特殊,它需要以指数的形式保存,先不讨论。我们先来讨论有符号的整数的存储。
对于有符号整数,我们可能认为,不管正负,直接按数据的二进制形式进行存储就可以,比如short a = 10的二进制是:
那么直接在计算机内存中直接存储这样一串二进制位就可以了。但事实上,对于正数来说,这样存储没有问题,但对于负数,这样的存储方式并不是最佳方式。对于负数,计算机存储的实际是数据的补码。下面先介绍数据的原码,反码,补码是什么,再介绍为什么要这样做。
- 原码:第一位表示符号位,其余位表示绝对值大小。
- 反码:正数的原码是其本身,负数的反码是符号位不变,其余位取反。
- 补码:正数的原码是其本身,负数的补码是除符号位外其余各位取反后加1。
由于正数的原码,反码,补码都是其本身,所以我们重点讨论负数的补码,以short j = -10为例,其他类型可以自行推导:
原码:
反码:
补码:
经过以上分析我们发现,short类型的-10,在内存中存储的实际是0xfffa这个补码。
使用补码还会引入另一个问题,那就是0的补码将有两个,以char类型为例:0000 0000和1000 0000都可以表示0。为了不引起歧义,把1000 0000定义为了-128的补码。所以C语言中0的补码就是用全零来表示。
使用补码的意义
对于有符号数,由于最高位表示数据的符号位,那么在参与计算时,这一位是不能参与数值运算的(尝试用原码计算5 + (-6),看看加出来的结果是什么),这对CPU来说,无疑是增加了设计的复杂度,因为计算机的各种计算都需要通过硬件电路来实现的,多一种特殊情况要考虑,设计的复杂度就增加一分。而采用补码的方式,则可以让计算机“忽略”符号位,在计算时,让符号位也可以直接参与数值运算(尝试再用补码计算5 + (-6),看看加出来的结果,注意结果也是补码形式)。
浮点数的存储
浮点数在内存中需要以指数的形式存储,比如:
float f = 3.1415926 = 0.31415926 * 10^1
那么,该数在内存中可以按下面的方式存储:
对于float类型来说,4个字节共32位中,究竟多少位用于表示底数部分,多少位用于表示指数部分,C标准并无具体的规定,由各编译器的实现来决定的。底数部分越多,则精度越高,指数部分越多,则能表示的范围越大。
数据的表示范围
计算机的内存终归有限,所以计算机不能存储一个无限大的整数,也不能存储一个无限精度的小数(比如0.11这样无法转化成2进制的数),用有限的内存去存储数据,我们需要知道数据的存储范围。
最好计算范围的数据类型是unsigned类型的整数,因为它的所有位都表示数值,那么一个n位的无符号数,其表示范围是0~2^(n-1),如下:
对于有符号数,因为其最高位用来表示符号位,所以,它所能表示的范围虽然和同类型的无符号数一致,但是最大值只有一半,如下:
对于浮点数,由于其存储的是指数与底数,所以还我们还需要衡量它的存储精度,一般用有效数字来表示,也由于浮点数存储不准确性(浮点数存储0.11时会有精度丢失),所以浮点数只可以进行范围大小的比较,不可以判断相等。
浮点数的比较
尤其注意,浮点数不可以使用 == 运算符去判断两个浮点数相等,并不是C语言语法规定不可以,而是实际运算的结果不准确,如下:
float num = 0.11;
if(num == 0.11) //这里实际上 num并不等于 0.11,因为num在存储到内存之后丢失精度
{
… //这段语句不会执行到
}
基于以上特点,对浮点数进行比较时,只可以对两浮点数在一定精度内进行比较,以两数之差的绝对值小于某个精度时作为判断依据,如下:
#include <math.h> //fabs()头文件
#define LIMIT 1e-6 // 精度
float num = 0.11;
if(fabs(num – 0.11) < LIMIT) //通过比较两浮点数之差的绝对值与规定精度判断浮点数相等
{
…
}
位运算
在了解了数据的存储形式之后,我们就可以对数据的每一个数据位进行操作了。C语言中,只可以对整数类型(int, char及其变体)进行位操作,浮点类型、结合类型、构造类型和指针是不可以进行位运算的。对C语言的位操作有下面几个:
- 按位左移 <<
将所有位向左移一位,最低位补充0。 - 按位右移 >>
将所有位向右移一位,如果是无符号数,最高位补充0。如果是有符号数,高位补0还是补1由编译系统决定,可能出现的情况有:算术右移(补充符号位),逻辑右移(补充0)。大部分编译系统执行算术右移。 - 按位与 &
- 按位或 |
- 按位取反 ~
- 按位异或
相同取0,不同取1
注意点:
- 优先级。移位运算符中,除~外,其他的位操作运算符优先级都低于算术运算,所以,像
0x01 << 2 + 3这样的表达式,先执行的是算术运算。 - 位运算中,移位操作时,移动的位数不能大于或等于数据的长度,不能小于0,否则编译器将结出警告。
- 对char类型或是short类型进行取反时,要考虑类型转换问题。
常量
常量的表示
程序运行过程中值不会改变的量称为常量,比如立即数,字符,数组名,字符串等。
常量的存储
注意,与变量不一样,并不是所有的常量都会占用栈空间,比如数组名就没有专门的存储地地方。而字符串常量则只存储在程序的只读数据段。有的常量还可以在编译时直接编译机器的指令里。
int a = 2; // 2可以作为指令中的立即数存储在代码区
printf("%d", 100); // 100可能存储在程序的数据区
常量的类型
常量也具有类型,默认情况下按如下进行处理:
- 程序中所有出现的浮点数都是double类型。
- 单个字符与整数默认是int类型。
- 如果整数超出了int的表示范围,它将被当作long 或 long long来处理。
如果想改变常量的类型,则可以在常量后面添加指定后缀u l f L,如下:
123 // int类型 123L或123l // long类型 123LL // long long类型 123u // unsigned int 类型 123ul // unsigned long 123ull // unsigned long long 3.14 // double类型 3.14f // float类型 3.14L // long double类型
类型转换
程序计算中经常会遇到不同的数据类型进行运算的情况,而不同的数据类型要么是内存长度不一样(比如int和char),要么是存储方式不一样(比如int和float)。当不同类型的数据进行运算时,首先就需要通过一些规则把它们转换为某种共同的类型,称为类型转换。那么该如何确定转换的规则呢?
C语言中,按照转换的类型,可以分为强制类型转换和隐式类型转换。而且,只可以对数组、结构体、联合体以外的数据进行转换,比如基本数据类型和指针类型,枚举类型。
强制类型转换
可以对数据进行强类型转换,以转换成所需要的类型,格式是:(类型)变量名,比如:
char c = 5; int i = (int)c; //将char类型强制转换成int类型 float f = 3.14; int j = (int)f; //将float类型强制转换成int类型
强制类型转换时,数据的数值变化的规则如下:
- 浮点转整数将舍弃浮点的小数位
- 有符号char, short转int时默认按数值大小来转换(int最高位填充符号位)
- 无符号char, short转int时按照:小转大高位填充0,大转小截取低位(int最高位填充0)
- int转char, short时按内存模型来转换(忽略int的符号位)
- char, short, int转浮点型时小数点后填充0
隐式类型转换(自动类型转换)
并不总是需要对数据进行显示地强制类型转换之后才可以进行运算,像下面这样的写法也是可以的,称为隐式类型转换,由编译器识别并完成转换:
char c = 5; int i = c; //隐式类型转换,char类型被自动转换成了int类型 int j = 3.14 + 5; //浮点数隐式转换成整型
隐式类型转换最常见的是以下几种情况:
- 赋值运算:自动把“=”右边的类型转换成“左边的类型,例如:int a = 4.5; a的值是4。
- 混合运算:当一个运算符两边的类型不一致时,需要先统一两边的类型,原则是把“较窄”的数据类型提升成“较宽”的数据类型,按下图所示:

- 参数传递:默认将实参转换成形参的类型
- 返回值传递:默认转换成函数的类型
指针的类型转换
不同类型的指针进行运算时,编译器会报警告,表示不允许操作,而对指针进行类型转换后,就可以骗过编译器,让它不报警告,方式如下:
char c; char* p = &c; int* p2 = (int *)p; //char型指针转换成int型指针 int* p3 = (int *)&c; //同上
对于指针的类型转换有特殊的作用,使用指针可以完成对同一片内存的任意形式的访问,甚至是完成对构造数据类型的转换。
char str[1024] = "12345"; int *pi= (int *)str; //以整型变量的方式访问str这个地址 short *ps = (short*)str; //以短整型变量的方式访问str这个地址 float *pf = (float*)str; //以浮点型变量的方式访问str这个个地址
void*
void*可以用于定义一个指向空类型的指针变量,它的特点是,任何类型的指针都可以用来给void*类型赋值且不会报错,而void*类型赋值给其他任何类型时都要进行强制类型转换之后才可以。void*类型最能发挥作用的地方是修饰函数的形参与返回值,可以作为指针的通用类型来使用,比如用于申请和释放堆内存的maclloc和free原型如下:
void *malloc(size_t size); void free(void *ptr);
大小端
CPU的大小端问题决定了数据的高位存储位置。小端系统中,数据的高位存在地址的高位,而大端系统中,数据的高位存在地址的低位,以int i = 0x12345678为例,以下是其在小端系统中和大端系统中的内存布局:
堆内存
到现在为止,我们还只能在栈上分配可读写的内存(通过定义变量的方式),但是栈的内存是有限的(典型值是8M,通过ulimit -s可查看),这意味着我们不可以用栈来存储较大的数据(比如在理论情况下,分配一个超过8M大小的数组就会造成程序栈溢出)。
当需要分配较大的内存时,使用栈内存就会变得非常危险。为此我们可以改为在程序的堆内存(heap)上分配空间。通过标准库函数malloc可以在堆上分配内存,方式如下:
int *p = NULL; p = (int *)malloc(sizeof(int) * 10); //在堆内存上分配40个字节的可用空间
堆内存与栈内存不同,栈内存的释放是由编译器自动完成的,而堆内存则需要手动释放,采用如下方式:
free(p); //释放由p指向的内存空间,具体大小 p = NULL; //p的值并没有改变,但是p所指的空间已经不可用了,安全起见,一定要对p设置为NULL
尤其注意的是,申请的地址和释放的地址要准确对应,且不可以对同一个地址多次调用free函数。
全局变量与静态变量
全局变量
全局变量是在函数之外定义的变量,它的作用域是从定义处开始到文件结束。全局变量存储的程序的数据段,在程序开始运行时就会创建,且在整个运行期间都存在,不会被销毁(想想main函数是不是函数的入口)。示例如下:
#include <stdio.h>
int global = 10;
int main()
{
printf("%d\n", global);
return 0;
}
静态变量
与全局变量类似的是静态变量,静态变量也存储在数据段,但是静态变量要在第一次调用时才会创建,然后在程序的整个运行期间都存在。示例如下:
void fun()
{
static int i = 0; //第一次调用fun()时创建并赋值,后面再次调用时不再创建,直接使用上次保存的值
i++;
}
int main()
{
fun(); // i = 0
fun(); // i = 1
}
内存图总览(bss段未画出)
