音频压缩的心理声学原理
频域遮蔽
一个频率的声音能量小于某个阈值之后,人耳就会听不到,这个阈值称为最小可闻阈值,也就是静音门槛。(PS: 不同频率的声音静音门槛不一样)
当有另外能量较大的声音出现的时候,该声音频率附近的阈值会提高很多,也就是说,即使附近频率的声音能量超过了静音门槛,人耳也听不见。
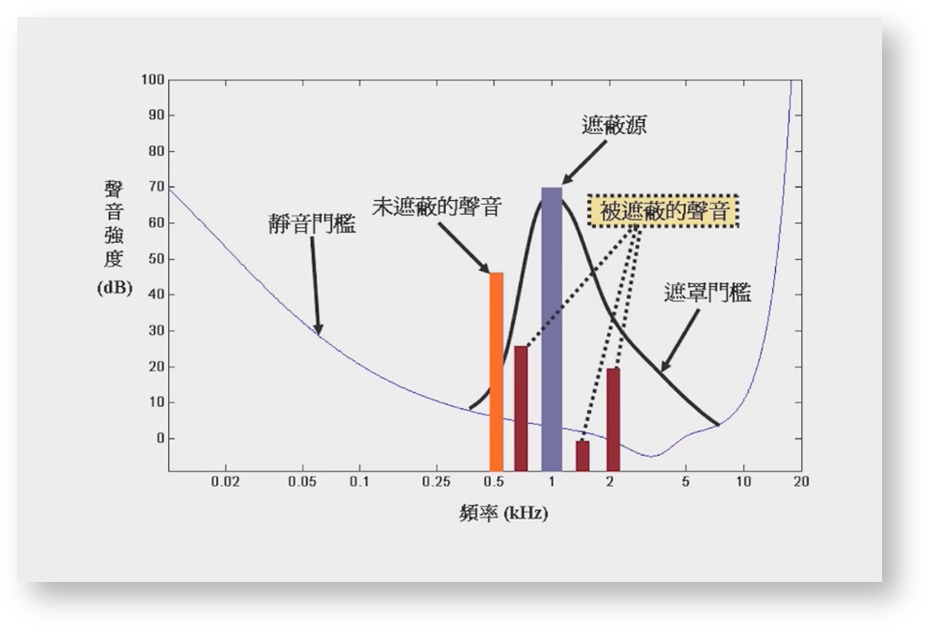
频域遮蔽对应的生活经验,比如多人同时说话时,大声容易掩盖掉小声。
频域遮蔽的多个声音必须同时出现,如果不是同时出现,则产生的遮蔽效应为时域遮蔽。
时域遮蔽
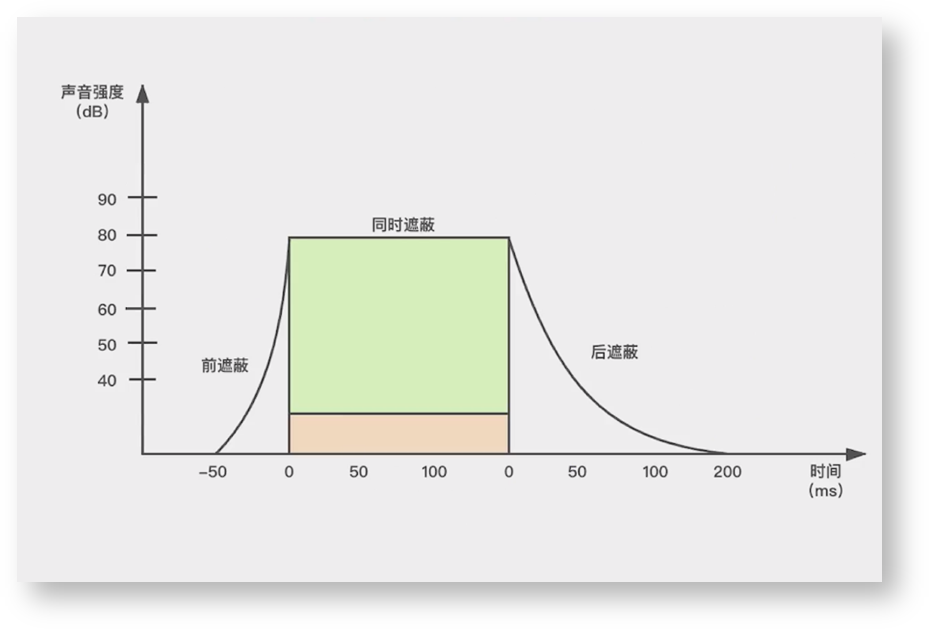
强音信号和弱音信号发生时间很接近时,会出现时域遮蔽。时域遮蔽分为前遮蔽、同时遮蔽、后遮蔽三部分。前遮蔽指人耳在听到强音信号之前的短暂时间内,已经存在的弱音信号会被遮蔽而听不到。同时遮蔽是指强音信号和弱音信号同时存在时,强信号会遮蔽弱信号。后遮蔽是指当强信号消失后,需要经过较长的一段时间才能重新听见弱信号。
音频压缩算法分类
分为有损压缩和无损压缩。有损压缩的原理就是前面的心理声学原理。根据压缩方案的不同,还可以划分时域压缩、变换压缩、子带压缩,以及多种技术相互融合的混合压缩。
时域压缩(或称为波形编码)
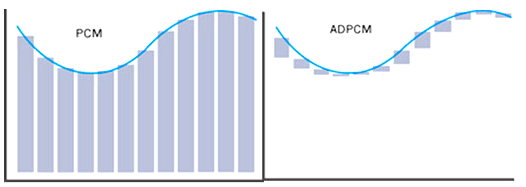
直接针对音频PCM码流的量化值进行处理,比如将原本16bit的采样值编码压缩到8bit。时域压缩采用的办法有静音检测、差分编码、非线性量化等,一般算法简单,实时性高,但压缩比小,声音质量一般,所以一般多用于语音压缩,低码率场景。时域压缩技术主要包括G711、ADPCM。
变换压缩
将音频的时域信号转换到频域,然后利用心理声学模型,移除不相关频带的信号,对不同频带的信号分配不同的比重,再进行编码压缩,比如MP3编码。
各种波形编码(LPCM/ADPCM/G711等)
从脉冲编码调制说起,脉冲编码调制包含三步:
- 采样
- 量化
- 编码
采样与采样率有关,一般有8k, 16k, 32k, 44.1k等。量化与位深有关,有8bit, 16bit等。最后一步编码,决定了是否对音频进行压缩,以及音频数据最终的内容。
LPCM
LPCM: linear pulse code modulation,线性量化编码,直接取量化后的值作为编码值,这种编码是音频的最原始编码,属于无损编码。CD音频使用的就是线性PCM编码,由此可以计算CD音频的数据量:
2声道 x 44.1k采样率 x 16bit = 1411.2kbps
ADPCM
基于DPCM,也就是差分脉冲编码调制(Differential Pulse Code Modulation)。
DPCM的工作原理是原始PCM相邻采样点之间通常是比较连续的,差值不会很大,所以可以用较小的bit位数来表示,比如只用4bit表示差值,这样只需要知道起始点的值和每个点的差值,就可以还原得到原来的序列。记录的差值序列就是DPCM数据, 这样数据量会小很多。(与视频中的P帧类似,存储与关键帧的差值)
这里说法有误,DPCM的差值实际是预测值与实际值的差值,而不是与前一个采样点的差值。DPCM使用了预测编码,预测器可以根据当前已采样的点来预测下一个点的值,但预测会有误差,所以要把差值记录起来,这样在解码时就可以通过预测模型和差值还原出原始的值。
DPCM使用固定的位数来表示差值,在遇到相邻采样点之间差异很大时会丢失精度,所以是有损压缩。可以通过使用更大的位数来增大精度,但数据量也会增大。
为了优化DPCM,提出了ADPCM(Adaptive Differential Pulse Code Modulation, 自适应差分脉冲编码调),其思想是先定义差值表(例如IMA ADPCM 中使用 89个固定差值, 取值从7到32767),差值表的范围放宽到16bit,此时差值在数组中的编号只需要6bit就可以表示(0 - 88), 再进一步只记录编号的变化值, 就将变化量压缩到了4bit。
G711
G.711是一种由国际电信联盟(ITU-T)订定音频编码方式,又称为ITU-T G.711。
G.711使用64Kbps的带宽,可将14bits转换成8bits。目前G.711有两个编码方式,A-law以及μ-law。A-law 编码是以 13-bit 带符号的线性音效样品输入并转换成 8 bit 的值如下:

A律13折线,u律15折线。A律输入13位,其实就是16bit量化后的高13位,u律输入14位,同样是16bit量化后的高14位。u律使用在北美和日本,A律使用在欧洲和其他地区。
A律13折线的由来:
将输入区间归一化到[0, 1],并按照低半区二等分分割7次,得到8个输入区间。
将量化输出区间也归一化到[0, 1],并平均分成8等份,得到正极的8根折线。
相同的操作在负极也重复一次,一共就有16根线,但纵坐标区间[-2/8, 2/8]内的4根折线斜率相同,可以算作一根折线,所以总共有13段折线。

假如使用8bit进行PCM量化,则每个码字的位宽为8bit,其结构如下表所示:
| 名称 | 位置 | 长度 | 含义 |
|---|---|---|---|
| 极性码 | b0 | 1bit | 表示电平的正负极 |
| 段落码 | b1b2b3 | 3bit | 表示落在哪根折线上 |
| 段内码 | b4b5b6b7 | 4bit | 表示在拆线中的位置 |
MP3格式与MP3编码标准
MP3概述
MP3既是一种音频压缩编码标准,也是一种音频文件封装格式。
MP3编码标准自1993年起由MPEG-1音视频压缩标准一起发布,定义于MPEG-1标准集合的第三部分,即MPEG-1 Audio Layer3。
MP3编码
略。
MP3格式封装
AAC格式与AAC编码标准
AAC概述
Advanced Audio Coding, 高级音频编码,用于取代MP3编码,在相同的码率下,音频质量更高。
AAC最开始是基于MPEG-2标准的一部分布的,后续在MPEG-4标准中重新集成了其特性,加入了SBR技术和PS技术,并提供了新的档次(规格)。
在MPEG-2标准中,AAC定义的档次如下:
AAC LC: 低复杂度档次,LC表示Low-Complexity。
AAC Main: 主档次。
AAC-SSR: 可分级采样率档次,Scalable Sample Rate。
在MPEG-4标准中,AAC定义的档次如下:
AAC-Main: 主档次。
AAC-Scalable: 可分级采样率档次。
AAC-Speech: 主要适用于语音编码。
AAC-SyntheticAudio: 以较低码率合成声音及语音信号。
AAC-HighQuality: 高质量档次。
AAC-LD: 低延迟档次。
AAC-NaturalAudio: 适用于自然声音信息的编码。
AAC-MobileAudioInternetworking: 适用于网络音频的扩展档次。
在随后更新的AAC标准中,增加了HE-AAC和HE-AAC V2:
HE-AAC: 高效率,用于音频流媒体,受限带宽。在AAC-LC基础上,使用SBR技术(Spectral Band Replication,频域子带复制)提升压缩效率。SBR的技术原理是,人的听觉通常对声音中的低频分量具有较高的辨识精度,而对声音的高频分量辨识精度较弱。音频编码时,对于低频和中频分量,由编码器直接编码,对于高频分量不直接编码,而是计算其依赖信息,把依赖信息作为编码附加信息进行传递,解码时根据依赖信息和中低频分量可以重建出高频分量。
HE-AAC V2: 在HE-AAC基础上,增加了PS技术(Parametric Stereo,参数化立体声),用于提升立体声音频的编码效率。PS的技术原理是,立体声音频通常由两路相关的单声道音频信号构成,由于两个声道之间具有一定的相关性,所以可以重点只对其中一路进行编码,而另一路只作为附加编码,以较小码率传输附加信息即可。
HE-AAC的各个档次之间的关系如图所示:

AAC编码
略。
AAC格式封装
与MP3格式类似,AAC也提供了对应的音频信号的文件封装格式,即AAC格式。在AAC的标准协议中,共定义了两种AAC格式:
- ADIF格式:Audio Data Interchange Format,即音频数据交换格式。
- ADTS格式:Audio Data Transport Stream,音频数据传输流。
ADIF格式用于单独的AAC音频文件封装,包括文件头和音频数据,而ADTS格式则用于网络流媒体传输,包含一个一个的ADTS帧。
ADIF格式
包含一个单独的ADIF Header()(文件头)和一个完整的Raw Data Stream()(音频流数据)。解码和播放ADIF格式的音频文件,需要从开始位置读取完整的文件头信息,再按顺序解析音频数据流。
ADTS格式
用于流媒体传输,没有独立的文件头和音频数据流,而是将文件头和音频流数据与同步字和差错校验信息组合为一个数据帧。
每个数据帧包括固定头、可变头、CRC校验和音频数据,固定头每一帧的数据都固定不变,用于为音频流媒体等连续传输场景下确认随机接入点。固定头的前12bit为同步字,固定为0xFFF,解码器在码流中查找该字段作为解码的起始位置。
参考链接:
- 心理声学 - 维基百科,自由的百科全书
- 音频压缩_百度百科
- 高级音频编码 - 维基百科,自由的百科全书
- 常用音频编码格式简介(PCM、G726、ADPCM、LPCM、G711、AAC) - 知乎
- G.711 - 维基百科,自由的百科全书