const
如果希望程序中的某个变量具有只可读,不可写的属性,那么可将变量定义成只读变量。定义成只读变量后,只要在程序中出现了对该变量的写操作(赋值),编译器就会检查到该错误并报错。
C语言通过const关键字来定义只读变量,如下:
const int i = 10; //定义只读变量i,它的值为10
int const i = 10; //该写法的意义同上
const int *p = NULL; //定义只读指针变量,它的值为NULL
const int a[10] = {0}; //定义只读数组a,它的所有元素都只可读
const char *p = "hello"; //定义只读字符指针p,它指向“hello”在数据段的地址
由于const定义的变量具有只读属性,所以const变量只能在定义时赋初值或是作为函数的形参时由实参赋初值。
有说法将const定义的变量称为const常量,这种称法非常具有误导性,让人误以为const定义的变量值不可以修改。而实际上,使用const修饰的变量,只是让变量具有可读不可写的属性——只能通过变量名读取变量,而不可以通过变量名去写入变量。如果我们不通过变量名,而是通过地址的形式,const变量仍可以修改,如下:
const int i = 1;
int *p = &i; // 这时编译器会给出警告,但仍能通过编译
*p = 10; // 通过指针p修改只读变量i的值
printf("%d\n", i); //i的值变成 10
const修饰指针
const修饰指针的情形非常常见且具有重要作用,需要分辨清楚 。const修饰指针一共有以下几种情况:
int a = 1; const int *p1 = &a; // p1的值可变,但不可以使用p1去修改a的值 int const *p2 = &a; // 同上 int *const p3 = &a; // 不可以修改p3的值,但可以通过p3去修改a的值 const int *const p4 = &a; // p4的值不可修改,也不能通过p4去修改a的值
可以按照下面的方法来理解和记忆const指针的用法:
先忽略类型名,看const离哪个近,“近水楼台先得月”,离谁近就修饰谁。
int a = 1; const int *p1 = &a; // const修饰*p1,*p1是指针指向的对象,该对象不可变 int const *p2 = &a; // 同上 int *const p3 = &a; // const修改p3,p3是指针,不可变,p3指向的对象可变 const int *const p4 = &a; // 前一个const修饰 *p4,后一个const修饰p4,p4和*p4都不可变
字符串常量中的const
平常我们也会将字符串称为字符串常量,而且字符串存储在只读数据区,它的值本身也不可以修改,那么,像下面这样的const用法,有必要吗?
char *p1 = "hello"; const char *p2 = "hello";
不管加不加const,"hello"这个字符串的内容都改不了,但是,加上const有一个好处,那就是在编译期间就可以检查出错误。而不加const时,程序只能在运行期间才检测到错误。一般我们都希望在编译期间就可以检查出程序的错误,所以const的作用还是很明显的。
*p1 = 'a'; // 编译可以通过,但运行之后会有段错误 *p2 = 'a'; // 编译不通过,防止在运行之后再发生错误
const修饰函数的参数
const也可以修饰函数的形式参数,当不希望这个参数值在本函数体内被意外改变时使用,例如:
void fun(const char *p);
这样,任何传入的参数都会当成const类型来对待。相当于告诉编译器,p这个指针所指向的类型不可以通过p来进行修改,从而防止函数调用者在无意中修改了p所指向的对象。建议指针类型的参数,如果不想通过指针修改对象的值,都要定义成const类型,比如字符串操作函数strcpy, strcat的源字符串都要用const修饰。
const除了可以修饰指针类型的参数之外,也可以修饰一个具体的值,表示这个值不可以在函数体内更改。但一般这样做没什么意义,因为被调函数只能获取实参一个副本,不定义成const类型也不会影响到实参的值。
const修饰函数返回值
const修饰函数的返回值时,如果返回值不是指针,是一个具体的对象,那么这种修改没有意义。当const修饰的函数返回值是指针时,表示不可以通过函数的返回值去修改指针所指的内存,如下:
char *p = "hello";
const char *fun(void)
{
return p;
}
*(fun()) = 0; // 编译不通过
const与define
const与define在某种程度上都可以用于定义“常量”,但是const与define还是有本质区别的,具体可以从以下几点进行分析:
- 编译器处理方式不同
define宏是在预处理阶段进行文本替换。
const只读变量是在编译运行阶段使用。 - 类型和安全检查
define宏没有具体的类型,仅仅在预编译时进行替换,不做类型检查。
const只读变量有具体的类型,在编译阶段会执行类型检查。 - 存储方式不同
define宏不占用存储空间。
const只读变量会在内存中分配空间。
PS: 在C++中,const还有更多的功能。
volatile
volatile是易变的、不稳定的意思,通过volatile关键字可以定义易变变量。volatile在嵌入式开发中具有举足轻重的作用,因为嵌入式开发人员要经常同中断、底层硬件等打交道,这些都要用到volatile,因此嵌入式开的程序员必须掌握volatile的使用。
要理解volatile的作用,我们需要先分析一下现代计算机的分级存储系统。现代计算机中,存储系统一般分为以下几级: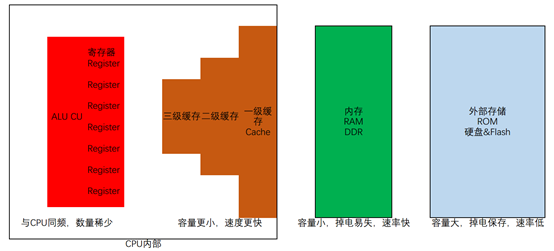
上述各部分中,与volatile有关的是寄存器部分。一般情况下,我们都认为数据是保存在内存中的,比如我们定义的各种变量就是保存在内存里面。但是,当一个数据需要频繁使用时,从内存把数据载入CPU或是从CPU将数据写回内存将消耗大量的时间。因此,可以把数据保存在寄存器里,因为寄存器的存取速度与CPU的计算速度相同,CPU计算的有多快,寄存器就可以以多快的速度进行存取。
编译器根据以上特点,在编译程序时,会对具有上述特点的一些变量(比如常见的循环控制变量)进行优化,将它们保存在寄存器中。
int i; // 理论上将i存储中寄存器中可以加快速度
for(i = 0; i < 100000000; i++)
{
// do something
}
但是,一味地为了速度去优化变量的存储位置是有问题的,如果这个变量被多个代码段所共享(比如全局变量),那么,将它保存在寄存器中,对它所做的改变将不能及时写入内存,同时,CPU也不能及时从内存得知该数据是否已经被改变。如果这个变量是一个关键的状态检测变量(比如CPU的中断变量),那么,它的状态改变就有可能在第一时间未被检测到。
所以,为了防止编译器自作主张地去改变变量的存储位置,可以用volatile修饰变量。准确说就是,每次要用到这个变量时,都必须从内存中直接读取这个变量的值,而不是使用在它在寄存器中的备份。
volatile int i; // 每次用于i时都要从内存去取值
for(i = 0; i < 100000000; i++)
{
// do something
}
优化的内容还不止这一个,编译器还会自动分析程序,将一些看似没有意义的语句进行优化(比如,连续对同一个变量多次赋值,编译器可会只取最后一次赋值,中间的赋值被省略)。同理,使用volatile修饰之后,类似的优化将被取消。
volatile int i; i = 1; // 这些代码不会被优化 i = 2; // 这些代码不会被优化 i = 3; // 这些代码不会被优化 i = 4;
总结一下volatile关键字的作用:
- 中断服务程序中修改的供其他程序检测的变量需要加volatile。
- 多任务环境下各任务间共享的变量应该加volatile。
存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能有不同的意义,以下是一种常见的写法:
#define GPIOCOUT *((volatile unsigned*)0xb000a000)
register
register关键字与volatile关键字作用刚好相反。使用register修饰后,编译器会尽可能将这个变量存储在CPU内存的寄存器中,而不是通过内存寻址去访问。
注意,CPU的寄存器是数量有限的,一般也就那么几个或是几十个,如果用户定义了很多的register变量,那么并不是所有的register变量都会真的存储在寄存器中。
register int i;
for(i = 0; i < 100000000; i++)
{
// do something
}
注意:
使用register修饰的变量必须是CPU寄存器所能接受的类型,这意味着register变量必须是一个值,且长度小于或等于整型数据的长度。因为register变量可能不存放在内存中,所以不能对register变量使用“&”进行取地址操作。
typedef
C语言提供了一个typedef关键字,它可以用来为数据类型重命名,使用方法如下:
typedef 数据类型 别名;
例如:
typedef int int32_t; //将int重命名为int32_t typedef uinsigned int uint32_t; //将unsigned int重命名为uint32_t typedef char Byte; //将char重命名为Byte
使用typedef,可以方便地为数据类型建议别名,简化程序的书写,方便程序的阅读,比如:
int32_t a; uint32_t b; Byte c;t
typedef指针
typedef char* String; // 将char* 类型重命名为String String p1, p2; ==> char *p1, *p2;
typedef数组
typedef int arr_t[10]; // arr_t的类型为int[10]; arr_t a; ==> int a[10];
typedef数组指针
typedef int (*arr_pointer_t)[10]; //arr_pointer_t的类型为int[10]* arr_pointer_t p; ==> int(*p)[10];
typedef结构体
struct test
{
int a;
};
typedef struct test struTest_t; //将struct test类型重命名为struTest_t
typedef struct
{
int a;
} struTest_t; //直接结构体将将类型定义为struTest_t结构体指针
typedef struct
{
int a;
} * pstruTest_t; //直接定义结构体指针类型pstruTest_t
struTest_t s; ==> struct test s;
pstruTest_t p; ==> struct test *p;
typedef函数指针
typedef int (*func_t)(int, int); // 定义函数指针类型 func_t f; ==> int(*f)(int, int);
typedef与#define的区别
- 处理阶段不一样,#define在预处理阶段处理,而typedef则在编译阶段处理。
- 功能不一样,typedef只可以为类型重命名,而#define的工作原理是替换,除了可以用来定义类型为,还可以用于定义常量,编译开关等。
- 作用域不一样,typedef有作用域,而#define的作用域是整个程序。
对指针的操作不一样,考虑以下定义:
typedef char String1; #define String2 char
那么,在用这两种类型定义指针时,差别如下:
String1 p1, p2; // p1和p2都是char*类型 String2 p1, p2; //这个宏会展开成char *p1, p2; 其中p1是char*类型,p2是char类型
多文件与extern
一般在一个完整的项目都是有很多源文件组成的,当项目由很多个源文件的时候,我们需要考虑怎么组合这些源文件。
最简单的情况是,将函数的定义放在一个源文件中,然后在另一个源文件中去使用它,如下:
// 1.c
void hello(void)
{
printf("hello, world\n");
}
// 2.c
int main()
{
hello();
}
此时,只需要将两个源文件一起进行编译即可。但是这种情况下,需要考虑函数的定义与声明问题,多个源文件参与编译时,每个函数只可以有一处定义,但是可以有多处声明,比如:
// 1.c
void hello(void); //在此处声明hello函数
void hello(void)
{
printf("hello, world\n");
}
// 2.c
void hello(void); //在此处也可以声明hello函数
int main()
{
hello();
}
为了加以区分,我们一般会在非定义处的那个文件加上extern关键字,表示当前这个源文件使用的定义是在外部定义的,如下:
// 1.c
void hello(void)
{
printf("hello, world\n");
}
// 2.c
extern void hello(void); //使用extern关键字,表示函数在外部定义
int main()
{
hello();
}
全局变量的extern
在一个源文件中定义的全局变量也可以被另一个源文件使用,但是和函数不一样,全局变量的引用需要强制使用extern关键字进行声明,否则会出现变量未定义情况。
// 1.c
int global = 1;
// 2.c
extern int global; //使用extern关键字,表示该变量在外部定义
int main()
{
printf("global is %d\n", global);
}
注意一点,使用extern声明全局变量时,不可以对全局变量进行赋值,如下:
extern int global = 2; // 错误,不可以赋值,因为这里只是对变量进行声明,并没有定义变量
static与作用域
C语言中,每个标识符都有自己的作用域,其中最好理解的是局部变量,它的作用域就是在它所处的那个{}以内的范围,定义之前和{}之外这个标识符将不再起作用,如下:
{
int a;
// 这行以下到最近的一个右大括号为a的作用域,a只能在这个作用域内使用
}
a = 1; // 错误,这里已经脱离了a的作用域,a不能再使用
第二种好理解的作用是全局变量的作用域,它从当前行开始到整个文件的结束,该标识符都有效。除此之外,全局变量还可以通过extern的方式在别的文件中使用。
但是,当多个文件一起编译时,关于作用域的讨论将变得复杂一些,因为涉及到了多个文件,标识符很有可能就会冲突,下面讨论一个多文件情况下限制标识符作用域的关键字-static。
static可以修饰普通的局部变量,表示这个变量是一个静态变量,它和全局变量一样长驻于内存的数据段,但是作用域只限于定义处的那个函数。除此之外,static也可以修饰全局变量和函数,以下分别讨论之。
static修饰全局变量
当static修饰全局变量时,这个全局变量在当前文件的使用性质并没有改变,依旧是一个全局变量,但是,不可以用extern将该文件引用到别的文件中去使用,否则会编译不通过,如下:
// 1.c
static int global = 1;
// 2.c
extern int global; //出错,不允许用extern声明一个static全局变量
int main()
{
printf("global is %d\n", global);
}
static修饰函数
当static修饰一个函数时,这个函数将变成一个内部接口,它只能在该文件中被其他的函数调用,而不可以被其他文件所调用,即使用extern进行声明也不行,如下:
// 1.c
static void hello(void)
{
printf("hello, world\n");
}
// 2.c
extern void hello(void); //出错,不允许用extern声明一个static函数
int main()
{
hello();
}
一般而言,出于模块化程序设计的考虑,只在当前文件中使用的函数和全局变量都应该声明成static类型,以避免在外部被使用。只有那些想开放给外部使用函数和全局变量才不需要加static。