音频压缩的声学原理
频域遮蔽
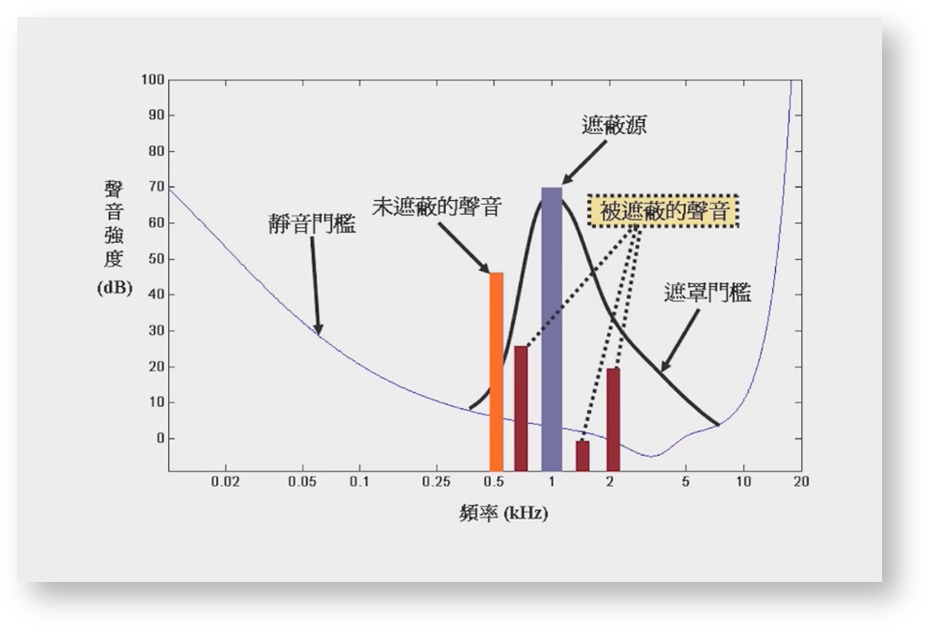
一个频率的声音能量小于某个阈值之后,人耳就会听不到,这个阈值称为最小可闻阈,也就是静音门槛。(PS: 不同频率的声音静音门槛不一样)
当有另外能量较大的声音出现的时候,该声音频率附近的阈值会提高很多,也就是说,即使附近频率的声音能量超过了静音门槛,人耳也听不见。
| 提示 |
|---|
频域遮蔽对应的生活经验,比如多人同时说话时,大声容易掩盖掉小声。 |
| 提示 |
|---|
频域遮蔽的多个声音必须同时出现,如果不是同时出现,则产生的遮蔽效应为时域遮蔽。 |
时域遮蔽
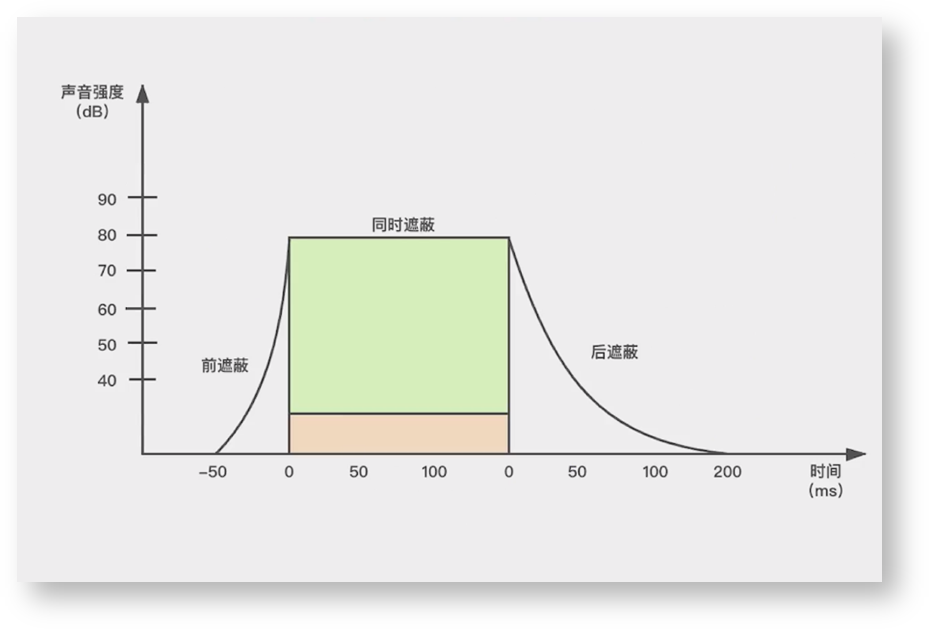
强音信号和弱音信号发生时间很接近时,会出现时域遮蔽。时域遮蔽分为前遮蔽、同时遮蔽、后遮蔽三部分。前遮蔽指人耳在听到强音信号之前的短暂时间内,已经存在的弱音信号会被遮蔽而听不到。同时遮蔽是指强音信号和弱音信号同时存在时,强信号会遮蔽弱信号。后遮蔽是指当强信号消失后,需要经过较长的一段时间才能重新听见弱信号。
音频压缩算法分类
利用音频的遮掩效应和心理声学原理,对音频数据进行压缩。一般分为有损压缩和无损压缩,根据压缩方案的不同,还可以划分时域压缩、变换压缩、子带压缩,以及多种技术相互融合的混合压缩。
时域压缩(或称为波形编码)
直接针对音频PCM码流的量化值进行处理,比如将原本16bit的采样值编码压缩到8bit。时域压缩采用的办法有静音检测、差分编码、非线性量化等,一般算法简单,实时性高,但压缩比小,声音质量一般,所以一般多用于语音压缩,低码率场景。时域压缩技术主要包括G711、ADPCM。首先是有损压缩和无损压缩。
参考链接:
| 目录 |
|---|